
壹 介绍
1.1 为什么要学习序列化与反序列化?
平时我们进行远程通信时,需要互相传输各种类型的数据,如:文本、图片、视频等,这些数据都可以通过二进制流的方式在网络上进行传送,并且有固定的MIME和后缀名进行识别,那么当两个Java进程进行通讯时,能否使用二进制流进行传输呢?当然可以,但是这种二进制流并没有固定的MIME和后缀名进行识别,而是以字节序列与对象进行转换传输的,我们又将这种转换称为序列化。发送方需要把一个Java对象传输给接收方时,发送方需要将这个Java对象转换为字节序列,然后通过网络传送到接收方,接收方接收到字节序列后,将其恢复成Java对象。当然,这种转换不仅仅是局限于Java这个语言,当然还包括其他语言,如PHP、Python等。
1.2 介绍
Java序列化是指把Java对象转换为字节序列的过程,Java中的ObjectOutputStream类里的writeObject()方法可以实现序列化,而Java反序列化是指把字节序列恢复为Java对象的过程,Java中的ObjectInputStream类里的readObject()方法可以实现反序列化。
1.3 应用场景
- 当我们需要把内存中的对象状态保存到一个文件中或者数据库的时候
- 当我们需要通过
Socket在网络上传输对象的时候 - 当我们需要通过
RMI传输对象的时候
RMI全称是Remote Method Invocation,远程方法调用。从这个名字就可以看出,它其实与RPC的功能应用场景应该是差不多的,他们的功能是让A程序调⽤B程序上的方法,实现程序间的方法的互相调用,这两个程序可以是运行在相同计算机上的不同进程中,也可以是运行在网络上的不同计算机中,只不过RMI是Java独有的一种机制。
1.4 Java序列化需要注意的点
1、需要对象继承
Serializable接口(这是一个空接口)或者Externalizable接口才能进行序列化操作
要被进行序列化的对象,该对象必须继承Serializable接口或者Externalizable接口,才能进行序列化操作。2、成员变量必须可以序列化
如果所要序列化的对象的成员属性中含有对其他对象的引用,要求所引用的对象也必须是可序列化的(也就是说实现serializable接口),否则会序列化失败。这是因为Java的序列化会将一个类中所有的成员变量,包括引用的成员变量保存下来(深度复制),这就会导致要求引用类型必须也要实现java.io.Serializable接口。3、
transient关键字,可避免被序列化
用transient修饰的属性,可以避免被序列化4、无法更新状态
由于Java序列化算法不会重复序列化同一个对象,如果对象的内容更改后,再次序列化,并不会再次将此对象转换为字节序列。5、类的
serialVersionUID必须与序列化时的版本号匹配serialVersionUID是序列化版本号,用来保证序列化后的字节序列没有被改动过,反序列化回来后和原来的程序是兼容的。serialVersionUID不会自动改变,而是留给程序员手动更改的一个版本号标志位。更改了序列化文件的程序员一并更改版本号提示后来的人文件被更改过。如果在反序列化时,类的serialVersionUID与序列化时的版本号不匹配,那么会抛出InvalidClassException异常,表示类的版本不兼容,无法进行反序列化。
贰 Java序列化和反序列化的实现
2.1 原生的反序列化api
在Java的JDK类库中存在原生的反序列化api,当然市面上也有第三方组件提供的反序列化api,例如:fastjson、jackson,这里我们至少对原生的反序列化进行学习。
首先介绍两个主角:Java中的ObjectOutputStream类里的writeObject()方法和Java中的ObjectInputStream类里的readObject()方法。
java.io.ObjectOutputStream类表示对象输出流,它的writeObject方法可以对参数指定的对象进行序列化,把得到的字节序列写到一个目标输出流中。java.io.ObjectInputStream类表示对象输入流,它的readObject方法从输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回。
2.2 调用实现序列化和反序列化api
我们定义了两个方法分别是用于序列化的Serializable_ok方法和用于反序列化的UnSerializable_ok方法,这两个方法的逻辑就是通过获取传递来的参数对其进行序列化和反序列化:
package com.demo.serializable;
import java.io.*;
public class Serializable01 {
public void Serializable_ok(Object obj) throws IOException {
// 新建一个serializable.ser文件用来存储后续序列化的数据
FileOutputStream fileOutputStream = new FileOutputStream("serializable.ser");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
// 将获取到的对象进行序列化,并存入到serializable.ser文件中
objectOutputStream.writeObject(obj);
objectOutputStream.close();
}
public Object UnSerializable_ok(String file) throws IOException, ClassNotFoundException {
// 获取file文件中的序列化内容
FileInputStream fileInputStream = new FileInputStream(file);
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
// 将序列化内容转换为Java对象,并返回
Object o = objectInputStream.readObject();
return o;
}
}
2.2 对于Java序列化需要注意点的代码实现
2.2.1 需要对象继承Serializable接口或者Externalizable接口才能进行序列化操作
要被进行序列化的对象,该对象必须继承Serializable接口或者Externalizable接口,才能进行序列化操作。这里我们创建了一个UserStudent1类,并且没有继承Serializable接口或者Externalizable接口,运行后出现错误警告:
package com.demo.serializable;
import java.io.IOException;
class UserStudent1 {
public String Name;
public UserStudent1(String name){
this.Name = name;
}
@Override
public String toString() { return "UserStudent1{" + "Name='" + Name + '\'' + '}'; }
}
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
UserStudent1 student = new UserStudent1("a7cc");
// 创建自定义序列化类
Serializable01 serializableOk = new Serializable01();
// 序列化
serializableOk.Serializable_ok(student);
// 反序列化
UserStudent1 s1 = (UserStudent1)serializableOk.UnSerializable_ok("serializable.ser");
System.out.println(s1);
}
}

2.2.2 成员变量必须可以序列化
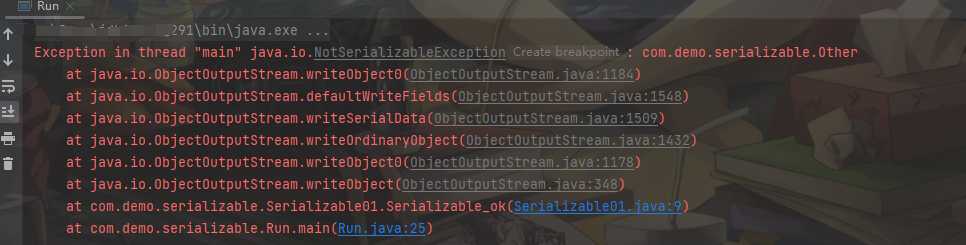
如果所要序列化的对象的成员属性中含有对其他对象的引用,要求所引用的对象也必须是可序列化的(也就是说实现serializable接口),否则会序列化失败。这是因为Java的序列化会将一个类中所有的成员变量,包括引用的成员变量保存下来(深度复制),这就会导致要求引用类型必须也要实现java.io.Serializable接口。下面代码中,Other类是没有继承了Serializable的,这时候就会报错:
package com.demo.serializable;
import java.io.IOException;
import java.io.Serializable;
// Other类是没有继承了Serializable的
class Other {}
// 如果继承了Serializable,就不会报错
// class Other implements Serializable {}
// UserStudent1类是继承了Serializable的
class UserStudent1 implements Serializable {
// String类是继承了Serializable的
public String Name;
// Other类是没有继承了Serializable的
public Other other;
public UserStudent1(String name,Other other){
this.Name = name;
this.other = other;
}
@Override
public String toString() { return "UserStudent1{" + "Name='" + Name + '\'' + ", Other='" + Other + '\'' + '}'; }
}
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
UserStudent1 student = new UserStudent1("a7cc",new Other());
// 创建自定义序列化类
Serializable01 serializableOk = new Serializable01();
// 序列化
serializableOk.Serializable_ok(student);
// 反序列化
UserStudent1 s1 = (UserStudent1)serializableOk.UnSerializable_ok("serializable.ser");
System.out.println(s1);
}
}
2.2.3 transient关键字,可避免被序列化
用transient修饰的属性,可以避免被序列化。
package com.demo.serializable;
import java.io.IOException;
import java.io.Serializable;
class UserStudent1 implements Serializable {
// Name没有被transient关键字修饰
public String Name;
// Other被transient关键字修饰
public transient String Other;
public UserStudent1(String name, String other){
this.Name = name;
this.Other = other;
}
@Override
public String toString() { return "UserStudent1{" + "Name='" + Name + '\'' + ", Other='" + Other + '\'' + '}'; }
}
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
UserStudent1 student = new UserStudent1("a7cc","11111111111");
// 创建自定义序列化类
Serializable01 serializableOk = new Serializable01();
// 序列化
serializableOk.Serializable_ok(student);
// 反序列化
UserStudent1 s1 = (UserStudent1)serializableOk.UnSerializable_ok("serializable.ser");
System.out.println(s1);
}
}
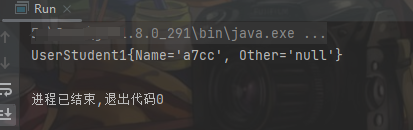
可以发现Other的值并不是11111111111而是为null,说明用transient修饰的属性是不能被序列化的。
2.2.4 无法更新状态
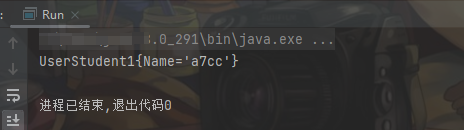
由于Java序列化算法不会重复序列化同一个对象,如果对象的内容更改后,再次序列化,并不会再次将此对象转换为字节序列。下面我们对student进行序列化两次,可以发现只对第一次序列化生效:
package com.demo.serializable;
import java.io.*;
class UserStudent1 implements Serializable {
public String Name;
public UserStudent1(String name){
this.Name = name;
}
@Override
public String toString() { return "UserStudent1{" + "Name='" + Name + '\'' + '}'; }
}
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
UserStudent1 student = new UserStudent1("a7cc");
// 创建自定义序列化类
// 新建一个文件用来存储后续序列化的数据
FileOutputStream fileOutputStream = new FileOutputStream("serializable.ser");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
// 将获取到的对象进行序列化,并存入到serializable.ser文件中
objectOutputStream.writeObject(student);
// 改变对象的Name值后再进行序列化
student.Name = "ok";
objectOutputStream.writeObject(student);
// 反序列化
// 获取file文件中的序列化内容
FileInputStream fileInputStream = new FileInputStream("serializable.ser");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
// 将序列化内容转换为Java对象,并返回
Object o1 = objectInputStream.readObject();
System.out.println(o1);
}
}
2.2.5 类的serialVersionUID必须与序列化时的版本号匹配
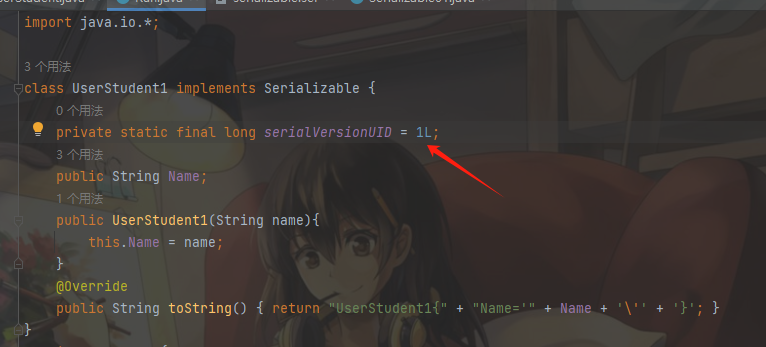
serialVersionUID是序列化版本号,用来保证序列化后的字节序列没有被改动过,反序列化回来后和原来的程序是兼容的。serialVersionUID不会自动改变,而是留给程序员手动更改的一个版本号标志位。更改了序列化文件的程序员一并更改版本号提示后来的人文件被更改过。Java的序列化机制是通过判断运行时类的serialVersionUID来验证版本一致性的,在进行反序列化时,JVM会把传进来的字节流中的serialVersionUID与本地实体类中的serialVersionUID进行比较,如果相同则认为是一致的,便可以进行反序列化,否则就会抛出InvalidClassException异常,表示类的版本不兼容,无法进行反序列化,即序列化ID是为了保证成功进行反序列化。我们在进行序列化时,加了一个serialVersionUID字段,这便是序列化ID。
2.2 实现序列化和反序列化的完整操作
要想对对象进行序列化和反序列化操作,那么就需要对象继承Serializable接口(这是一个空接口)或者Externalizable接口,才能进行序列化操作,否则会报错。例如下面这个例子,我们定义一个UserStudent类,该类继承了Serializable接口:
package com.demo.serializable;
import java.io.Serializable;
public class UserStudent implements Serializable {
// 名字
public String Name;
// 年龄
private int Age;
// 无参构造方法
public UserStudent(){}
// 有参构造方法
public UserStudent(String name){
this.Name = name;
}
// 多个有参
public UserStudent(String name,int age){
this.Name = name;
this.Age = age;
}
// 私有的构造方法
private UserStudent(int age){
this.Age = age;
}
public void Run1(){ System.out.println("上课1"); }
private String Run2(String name){ return "上课2"+name; }
@Override
public String toString() { return "Student{" + "Name='" + Name + '\'' + ", Age=" + Age + '\'' + '}'; }
}
接着编写一个简单的运行程序来运行序列化和反序列化操作,这里的Serializable01类在前面已经实现了:
package com.demo.serializable;
import java.io.IOException;
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
UserStudent student = new UserStudent();
student.Name = "a7cc";
// 创建自定义序列化类
Serializable01 serializableOk = new Serializable01();
// 序列化
serializableOk.Serializable_ok(student);
// 反序列化
UserStudent s1 = (UserStudent)serializableOk.UnSerializable_ok("serializable.ser");
System.out.println(s1);
}
}
可以发现运行后会有一个serializable.ser生成,并且内容是乱码,这就是序列化后的数据:
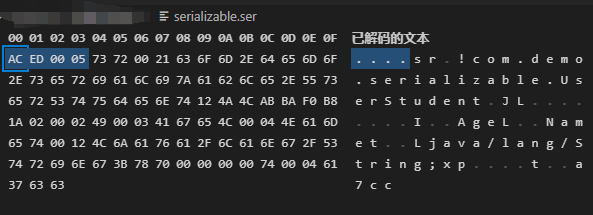
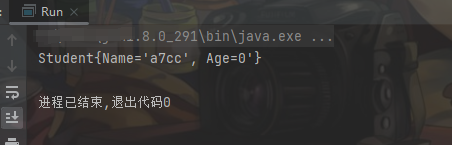
上图中的AC ED表示头部(Header),Java序列化文件的标识符,00 05表示版本号,版本号为5,剩下后面就是该对象被序列化后的数据,我们也能很清晰的看到类的名字、变量的值等信息。反序列化后输出的内容:
叁 Java反序列化安全问题
3.1 readObject方法与writeObject方法
通过上面的例子和代码,我们可以发现序列化存储的东西仅仅只是成员变量,而类内部的方法是不会存储的,所以如果我们仅仅只是使用前面的objectOutputStream实现的writeObject方法和objectInputStream实现的readObject,那么在很大程度上存在一定的局限性,加上有可能有一些属性我们只需要其中的一部分,例如一个属性是200长度的数组,实际上我们只需要其中的20个,这时候需要通过transient将其去除,但是其中需要的20个长度就需要通过另一种方式获得,基于这两个条件,这时候我们就要在当前对象类里去重写writeObject或者readObject方法,使得更加灵活,具体重写的格式:
private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException
private void readObject(java.io.ObjectInputStream s)throws java.io.IOException, ClassNotFoundException
要怎么编写呢?以writeObject为例,我们先在要被序列化的对象中定义writeObject方法:
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOE xception{
// 先调用 defaultWriteObject() 方法序列化对象中非transient修饰的属性
s.defaultWriteObject();
// 然后实现被transient修饰的属性进行自定义序列化,在要将其序列化的时候使用s.writeObject方法进行自定义序列化
。。。。
s.writeObject(xxxxx);
}
举一个例子:
package com.demo.serializable;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
class UserStudent1 implements Serializable {
// Name没有被transient关键字修饰
public String Name;
// Other被transient关键字修饰
public transient int[] Other;
public UserStudent1(String name){
this.Name = name;
this.Other = new int[100];
// 给前面30个元素进行初始化
for (int i = 0; i < 30; i++) {
this.Other[i] = i;
}
}
// 重写实现writeObject方法
private void writeObject(ObjectOutputStream s) throws IOException {
// 先调用 defaultWriteObject() 方法序列化对象中非transient修饰的属性
s.defaultWriteObject();
// 然后实现被transient修饰的属性进行自定义序列化,在要将其序列化的时候使用s.writeObject方法进行自定义序列化
for (int i = 0; i < 30; i++){
s.writeObject(Other[i]);
}
}
// 重写实现readObject方法
private void readObject(ObjectInputStream s) throws IOException, ClassNotFoundException {
// 先调用 defaultReadObject() 方法反序列化对象中非transient修饰的属性
s.defaultReadObject();
// 然后实现被transient修饰的属性进行自定义序列化,在要将其序列化的时候使用s.readObject方法进行自定义序列化
Other = new int[30];
for (int i = 0; i < 30; i++) {
Other[i] = (int) s.readObject();
}
}
@Override
public String toString() { return "UserStudent1{" + "Name='" + Name + '\'' + ", Other='" + Other + '\'' + '}'; }
}
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
UserStudent1 student = new UserStudent1("a7cc");
// 创建自定义序列化类
Serializable01 serializableOk = new Serializable01();
// 序列化
serializableOk.Serializable_ok(student);
// 反序列化
UserStudent1 s1 = (UserStudent1)serializableOk.UnSerializable_ok("serializable.ser");
System.out.println(s1);
}
}
3.2 反序列化漏洞
由于Java运行开发者重写readObject方法,并且该方法会自动执行,这就使得攻击者在服务器上拥有运行代码的能力,这就存在了一定的安全风险。例如下面这段代码,我们在UserStudent类里重写了readObject这个方法,并且在方法内加入了恶意代码:
package com.demo.serializable;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
class UserStudent1 implements Serializable {
public String Name;
public UserStudent1(String name){
this.Name = name;
}
// 重写了readObject这个方法,并且方法内加入了恶意代码
private void readObject(ObjectInputStream s) throws IOException, ClassNotFoundException {
s.defaultReadObject();
// 加入了弹计算器的代码
Runtime.getRuntime().exec("calc");
}
@Override
public String toString() { return "UserStudent1{" + "Name='" + Name + '\'' + '}'; }
}
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
UserStudent1 student = new UserStudent1("a7cc");
// 创建自定义序列化类
Serializable01 serializableOk = new Serializable01();
// 序列化
serializableOk.Serializable_ok(student);
// 反序列化
UserStudent1 s1 = (UserStudent1)serializableOk.UnSerializable_ok("serializable.ser");
System.out.println(s1);
}
}
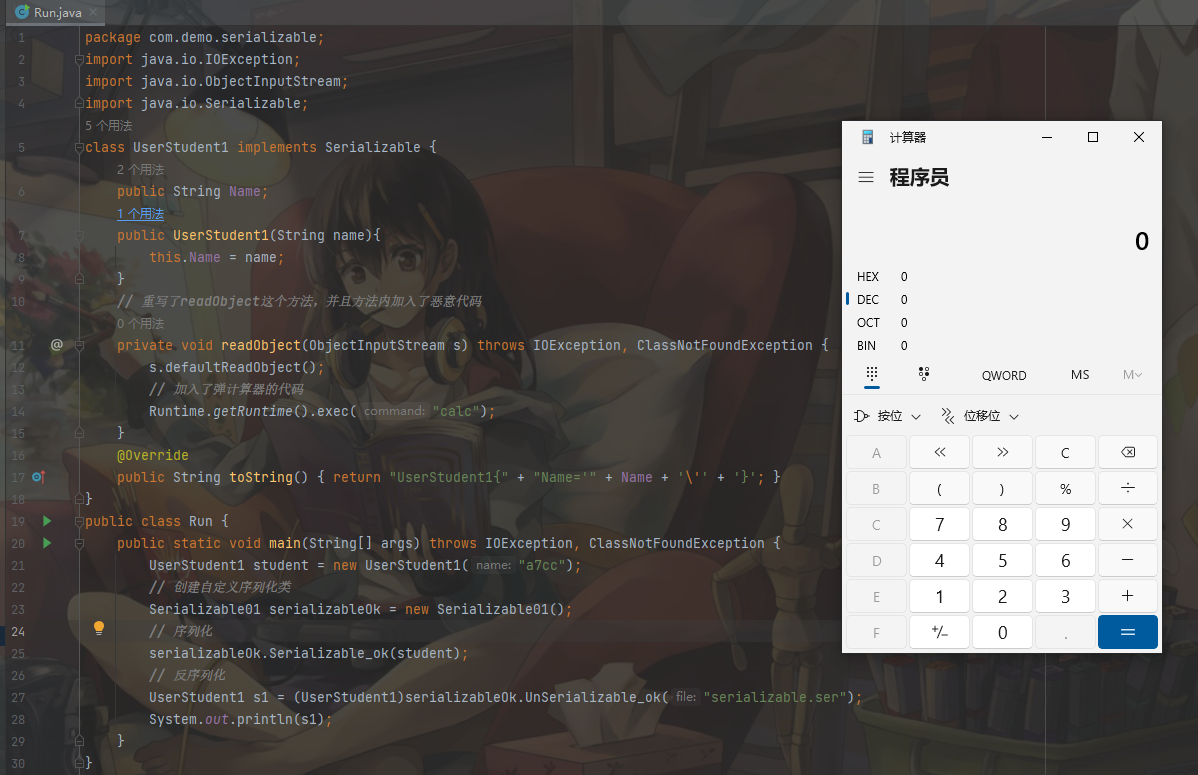
可以发现弹出了计算器,实现了我们需要的恶意代码。为什么我们要找反序列化的漏洞,而不是序列化漏洞?首先序列化一般是在我们机器的本地,然后经过序列化后传入到服务器中,进行反序列化,所以序列化一般是在本地,去挖掘该漏洞,显然没有任何意义,当然除非通过社工的方式将写好的序列化RCE文件给别人,远控其他人,这时候我们为啥不直接丢给木马呢?这样性价比肯定比序列化漏洞来的更实在,而反序列化一般发生在服务器,payload是我们可控的,所以我们更多是挖掘反序列化漏洞。
3.3 反序列化漏洞条件
通过前面的例子我们可以重写readObject方法,并且可以造成RCE,但是根据上面的例子我们可以很清楚的发现,该RCE的情况比较苛刻,首先服务器本地代码中必须存在一个类重写了readObject,然后重写的readObject里还需要存在恶意代码,并且该类还需要知道内部结构,很明显这是只有在CTF中出题人专门编写的代码才有可能存在这种情况,现实生活中,应该不会有这种奇葩的事情操作,那么除了这种方法我们还有其他的方法可以利用反序列化漏洞吗?
- 入口类的
readObject直接调用危险操作 - 入口类参数中包含可控类,该类有危险方法,且
readObject时调用 - 入口类参数中包含可控类,该类调用了其他有危险方法的类,且
readObject时调用 - 构造函数或静态代码块等类加载时隐式执行
这里需要说明入口类,就是上面例子中的UserStudent1类,说白了,入口类是我们使用程序输入数据最先接触的类。
3.3.1 入口类的readObject直接调用危险操作
这种操作其实就是前面弹计算机的操作,我们需要把恶意的代码写到服务器其中一个类中,然后调用该类,该方法前面也说了基本上可以忽略。
3.3.2 入口类参数中包含可控类,该类有危险方法,且readObject时调用
在反序列化时虽然没有直接执行恶意操作,但是在readObject时调用了该类存在的其他方法间接执行危险方法,造成RCE等,举个例子:A类重写了readObject方法,并且readObject方法内没有恶意代码,但是该类的其他方法存在一些危险操作,如http请求、文件上传等,这时候如果A类重写的readObject方法内调用了这些危险方法,那么就可能存在反序列化漏洞。这个场景其实和URLDNS链差不多。
3.3.3 入口类参数中包含可控类,该类调用了其他有危险方法的类,且readObject时调用
这种方式其实就是第二种方式再套一层类,有点像套娃,一层套一层,并且这些危险类的调用是在readObject时调用的。说白了就是那些利用链。
3.3.4 构造函数或静态代码块等类加载时隐式执行
这种方式其实就是构造函数或者静态代码块在程序运行前会进行类的加载并且做一些初始化操作,可能会调用一些危险方法或者是人为写入一些危险方法,这些都是默认执行的,这种方式相对比较底层,可以看一些关于类初始化的视频或者文章来进行研究。个人感觉从某种意义上并不是反序列化漏洞,而是由于其在初始化类时执行的,无论是什么类都会执行里面的代码,故感觉不算是反序列化漏洞。
3.4 反序列化漏洞流程
对于反序列化漏洞,首先我们需要有一个入口类,该类需要满足可以序列化和反序列化、重写readObject方法、并且在readObject时调用其他类或者危险方法,如果需要通过其他类去完善该利用链,那么同样需要找到对应的调用链子,直到出现可执行的sink点,这时候就是一个反序列化漏洞流程。
