
壹 简介
1.1 定义
进程:是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。即能够完成多个任务,一般而言,一个进程就是一个独立的软件,如我们在电脑上运行了多个 QQ,进程就是运行着的程序。
程序在还没有运行的时候,它们的程序代码文件存储在磁盘中,就是那些扩展名为.exe文件,双击它们,这些.exe文件就被os加载到内存中,运行起来,成为进程。
线程:有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程 ID,当前指令指针(PC),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。就绪状态是指线程具备运行的所有条件,逻辑上可以运行,在等待处理机;运行状态是指线程占有处理机正在运行;阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。每一个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。即能够完成多个任务,一般而言,一个进程至少存在一个线程或者多个线程,如打开网页,启动多个页面选项卡。下图是线程的几种状态: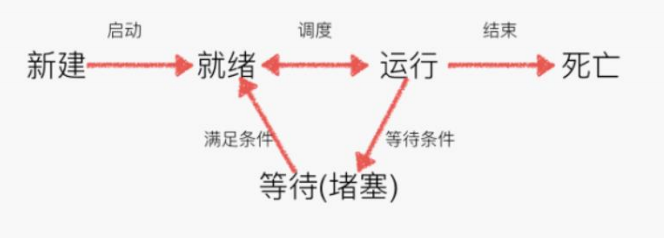
系统中每个进程里面至少包含一个线程,线程是操作系统创建的,每个线程对应一个代码执行的数据结构,保存了代码执行过程中的重要的状态信息。我们写的Python程序,里面虽然没有创建线程的代码,但实际上,当Python解释器程序运行起来(成为一个进程),OS就自动的创建一个线程,通常称为主线程,在这个主线程里面执行代码指令。
1.2 区别
a、一个程序中至少有一个进程,一个进程中至少有一个线程
b、线程的划分尺度小于进程(占有资源),使得多线程程序的并发性高
c、进程运行过程中拥有独立的内存空间,而线程之间共享内存,从而极大的提高了程序的运行效率
d、线程不能独立运行,必须存在于进程中
线程库:
multiprocessingmultiprocessing是一个支持使用与threading模块类似的 API 来产生进程的包。multiprocessing包同时提供了本地和远程并发操作,通过使用子进程而非线程有效地绕过了 全局解释器锁。 因此,multiprocessing模块允许程序员充分利用给定机器上的多个处理器。 它在 Unix 和 Windows 上均可运行。multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。线程库:
threading
Python的线程操作在旧版本中使用的是thread模块,在Python27和Python3中引入了threading模块,同时thread模块在Python3中改名为_thread模块,threading模块相较于thread模块,对于线程的操作更加的丰富,而且threading模块本身也是相当于对thread模块的进一步封装而成,thread模块有的功能threading模块也都有,所以涉及到多线程的操作,推荐使用threading模块。threading模块中包含了关于线程操作的丰富功能,包括:常用线程函数,线程对象,锁对象,递归锁对象,事件对象,条件变量对象,信号量对象,定时器对象,栅栏对象。
1.3 优缺点
线程开销小,但是不利于资源的管理和保护,而进程反之。如果需要利用电脑多个CPU核心的运算能力,可以使用Python的多进程库。
贰 安装
线程库threading库为内置库,不需要安装。
进程库multiprocessing库
叁 方法说明
3.1 threading库
3.1.1 主要函数
# 创建 Thread 类的实例对象
# target参数指定新线程要执行的函数名
# args参数是所调用函数的参数
# daemon参数是将该线程设置为守护线程,一般为False,线程不会随主线程退出而退出,为True时,当主线程结束,其他子线程就会被强制结束
# 注意,这里指定的函数对象只能写一个名字,不能后面加括号,如果加括号就是直接在当前线程调用执行,而不是在新线程中执行了
t = threading.Thread(target,args,daemon)
# 执行start 方法,就会创建新线程
t.start()
# join方法是主线程把任务分配给几个子线程,等待子线程完成工作后,需要对他们任务处理结果进行再处理,用在使用共有数据的情况,timeout是可选的超时时间。
t.join([timeout])
# 创建锁对象,一般在执行共享数据的时候使用
threading.Lock()
# 操作共享数据前,申请获取锁与release方法配套使用,用于堵塞其他线程调用未执行完的共享数据
threading.Lock.acquire()
# 操作完共享数据后,申请释放锁
threading.Lock.release()
3.1.2 辅助函数
注意:有一些方法是有多个方法名,但是功能一样,这里只列举其中一个。
# 返回线程是否活动的
t.isAlive()
# 设置线程名,name就是要设置的线程名字
t.setName(name)
# 返回线程名
t.getName()
# 返回线程是否为守护线程
t.isDaemon()
# 设置线程为守护线程,只能在start函数前面使用,bool为布尔值,一般为False,线程不会随主线程退出而退出,为True时,当主线程结束,其他子线程就会被强制结束
t.setDaemon(bool)
# 返回当前的线程变量
threading.currentThread()
# 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程
threading.enumerate()
# 返回正在运行的线程数量,与len(threading.enumerate()) 有相同的结果
threading.activeCount()
3.2 multiprocessing库
3.2.1 主要函数
# 创建一个Process对象
# group参数未使用,值始终为None
# target表示调用对象名,即子进程要执行的任务
# args表示调用对象的位置参数元组,args=(1,2,'mike',)
# kwargs表示调用对象的字典,kwargs={'name':'mike','age':18}
# name为子进程的名称
p = multiprocessing.Process([group[,target[,name[,args[,kwargs]]]]])
# 启动进程,并调用该子进程中的p.run()
p.start()
# 强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.terminate()
# 如果p仍然运行,返回True
p.is_alive()
# 主进程等待p终止(强调:是主进程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间。
p.join([timeout])
3.2.2 辅助函数
# 默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.daemon
# 进程的名称
p.name
# 进程的pid
p.pid
3.2.3 进程池
Pool 类表示一个工作进程池,可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。它具有允许以几种不同方式将任务分配到工作进程的方法,进程池的方法只能由创建它的进程使用。
# 创建进程池,processes为要创建的进程数量
pool = multiprocessing.Pool(processes)
# 该函数用于传递不定参数,同python中的apply函数一致,主进程会被阻塞直到函数执行结束
pool.apply(func[, args=()[, kwds={}]])
# 与apply用法一致,但它是非阻塞的且支持结果返回后进行回调,建议使用这个
# 参数统一说明:func是要调用的函数名,args是参数,以元组形式,kwds是函数的字典
pool.apply_async(func[, args=()[, kwds={}[, callback=None]]])
# Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到结果返回。注意:虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
pool.map(func, iterable[, chunksize=None])
# 与map用法一致,但是它是非阻塞的。
pool.map_async(func, iterable[, chunksize[, callback]])
# 关闭进程池(pool),使其不在接受新的任务
pool.close()
# 结束工作进程,不在处理未处理的任务,不管任务是否完成,立即终止
pool.terminal()
# 主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用
pool.join()
肆 使用
4.1 threading库
4.1.1 创建新线程
print('主线程执行代码')
# 从 threading 库中导入Thread类
from threading import Thread
from time import sleep
# 定义一个函数,作为新线程执行的入口函数
def threadFunc(arg1,arg2):
print('子线程 开始')
print(f'线程函数参数是:{arg1}, {arg2}')
sleep(5)
print('子线程 结束')
# 创建 Thread 类的实例对象
thread = Thread(
# target 参数 指定 新线程要执行的函数
# 注意,这里指定的函数对象只能写一个名字,不能后面加括号,
# 如果加括号就是直接在当前线程调用执行,而不是在新线程中执行了
target=threadFunc,
# 如果 新线程函数需要参数,在 args里面填入参数
# 注意参数是元组, 如果只有一个参数,后面要有逗号,像这样 args=('参数1',)
args=('参数1', '参数2')
)
# 执行start 方法,就会创建新线程,
# 并且新线程会去执行入口函数里面的代码。
# 这时候 这个进程 有两个线程了。
thread.start()
# 主线程的代码执行 子线程对象的join方法,
# 就会等待子线程结束,才继续执行下面的代码
thread.join()
print('主线程结束')
4.1.2 共享数据的访问控制
使用 threading库里面的锁对象 Lock 去保护共享数据。
from threading import Thread,Lock
from time import sleep
bank = {
'text' : 0
}
bankLock = Lock()
# 定义一个函数,作为新线程执行的入口函数
def deposit(theadidx,amount):
# 操作共享数据前,申请获取锁
bankLock.acquire()
balance = bank['text']
# 执行一些任务,耗费了0.1秒
sleep(0.1)
bank['text'] = balance + amount
print(f'子线程 {theadidx} 结束')
# 操作完共享数据后,申请释放锁
bankLock.release()
theadlist = []
for idx in range(10):
thread = Thread(target = deposit,
args = (idx,1)
)
thread.start()
# 把线程对象都存储到 threadlist中
theadlist.append(thread)
for thread in theadlist:
thread.join()
print('主线程结束')
print(f'最后我们的账号余额为 {bank["text"]}')
4.1.3 守护进程
主线程是守护线程,启动的子线程缺省也是守护线程。所以,要等到主线程和子线程 都结束,程序才会结束。我们可以在创建线程的时候,设置daemon参数值为True:
from threading import Thread
from time import sleep
def threadFunc():
sleep(2)
print('子线程 结束')
thread = Thread(target=threadFunc,
daemon=True # 设置新线程为daemon线程
)
thread.start()
print('主线程结束')
4.2 multiprocessing库
4.2.1 简单的使用
from multiprocessing import Process
def f():
while True:
b = 53*53
# 这个例子是看任务管理器,没有输出
if __name__ == '__main__':
plist = []
for i in range(2):
p = Process(target=f)
p.start()
plist.append(p)
for p in plist:
p.join()
4.2.2 进程池
#coding: utf-8
import multiprocessing
import time
a = 1
result = []
def func(msg,i,b):
print("{}--进程:{}".format(i, msg))
time.sleep(3)
b = b + 1
print("end:{}".format(msg))
return b
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 5)
for i in range(10):
msg = "hello 进程{}".format(i)
result.append(pool.apply_async(func, (msg, i, a,))) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print("主进程啊!")
pool.close()
#调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
pool.join()
for res in result:
print("输出:{}".format(res.get()))
print("结束done!a={}".format(a))
