
一、枚举
1.什么是枚举?
起初 Python 中并未内置枚举(enum)类型,枚举是在 Python3.4 添加的新功能,此时我们可能会有一个疑问:Python3.4 之前的版本还能不能使用枚举呢?
答案是可以使用,但是不能直接使用,使用之前需要先用pip install enum安装。
枚举可看作是一系列符号名称的集合,集合中每一个元素要保证唯一性和不可变,因此我们可以对枚举中元素进行恒等比较,通俗来讲枚举就是一系列常量的集合,枚举是可迭代的。
2.枚举有什么作用?
我们先来思考一个问题:不使用枚举我们如何定义常量呢?
常用的做法是采用变量名大写的方式来定义,这种方式虽然简单,但问题在于我们定义的仍然是变量、是可以被修改的,而常量是什么呢?简单来说就是不可变的量,枚举就有不可变的特性,所以枚举的主要作用就是用来定义常量的。
3.使用
a.创建
枚举语法与 class 语法相同,之前我们在Python 基础(十一):面向对象中已经介绍过 class 了,枚举的定义可以通过继承 Enum 的方式来实现, 看一下示例:
from enum import Enum
class WeekDay(Enum):
Mon = 0
Tue = 1
Wed = 2
Thu = 3
Fri = 4
b.访问
枚举成员及属性的访问如下所示:
# 枚举成员
print(WeekDay.Mon)
# 枚举成员名称
print(WeekDay.Mon.name)
# 枚举成员值
print(WeekDay.Mon.value)
枚举的迭代也很简单,如下所示:
# 方式 1
for day in WeekDay:
# 枚举成员
print(day)
# 枚举成员名称
print(day.name)
# 枚举成员值
print(day.value)
# 方式 2
print(list(WeekDay))
c.比较
枚举成员及属性可以使用is进行对象比较,还可以使用==进行值比较,看下示例:
print(WeekDay.Mon is WeekDay.Thu)
print(WeekDay.Mon == WeekDay.Mon)
print(WeekDay.Mon.name == WeekDay.Mon.name)
print(WeekDay.Mon.value == WeekDay.Mon.value)
枚举成员不能进行大小比较,如下所示:
>>> WeekDay.Mon < WeekDay.Thu
TypeError: '<' not supported between instances of 'WeekDay' and 'WeekDay'
d.确保枚举值唯一
我们定义枚举时,成员名称是不可以重复的,但成员值是可以重复的,如果想要保证成员值不可重复,可以通过装饰器@unique来实现,如下所示:
from enum import Enum, unique
@unique
class WeekDay(Enum):
Mon = 0
...
二、命名空间
1.概念
命名空间(namespace)是名称到对象的映射,当前大部分命名空间都是通过 Python 字典来实现的,它的主要作用是避免项目中的名字冲突,每一个命名空间都是相对独立的,在不同的命名空间中可以同名,在相同的命名空间中不可以同名。
2.种类
命名空间主要有以下三种:
内置:主要用来存放内置函数、异常等,比如:abs 函数、BaseException 异常。
全局:指在模块中定义的名称,比如:类、函数等。
局部:指在函数中定义的名称,比如:函数的参数、在函数中定义的变量等。
3.生命周期
通常在不同时刻创建的命名空间拥有不同的生命周期,看一下三种命名空间的生命周期:
内置:在 Python 解释器启动时创建,退出时销毁。
全局:在模块定义被读入时创建,在 Python 解释器退出时销毁。
局部:对于类,在 Python 解释器读到类定义时创建,类定义结束后销毁;对于函数,在函数被调用时创建,函数执行完成或出现未捕获的异常时销毁。
三、作用域
1.概念
作用域是 Python 程序可以直接访问命名空间的文本区域(代码区域),名称的非限定引用会尝试在命名空间中查找名称,作用域是静态的,命名空间是随着解释器的执行动态产生的,因此在作用域中访问命名空间中的名字具有了动态性,即作用域被静态确定,被动态使用。
2.种类
Python 有如下四种作用域:
局部:最先被搜索的最内部作用域,包含局部名称。
嵌套:根据嵌套层次由内向外搜索,包含非全局、非局部名称。
全局:倒数第二个被搜索,包含当前模块的全局名称。
内建:最后被搜索,包含内置名称的命名空间。
作用域的搜索顺序通过下图直观的来看一下: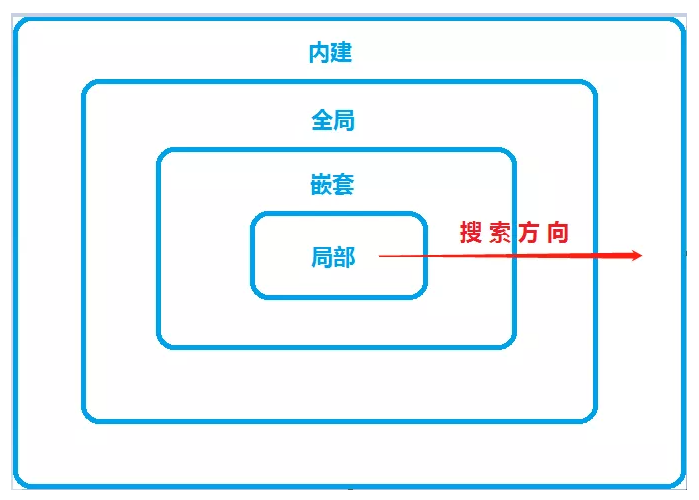
Python 中会按上图所示作用域由内向外去搜索名字。
再通过具体代码来对作用域作进一步了解,如下所示:
# 全局作用域
g = 1
def outer():
# 嵌套作用域
e = 2
def inner():
# 局部作用域
i = 3
3.global & nonlocal
我们先来看一下全局变量与局部变量。
- 全局变量:定义在函数外部的变量。
- 局部变量:定义在函数内部的变量。
全局变量可以在整个程序范围内进行访问,而局部变量只能在函数内部访问。通过具体示例看一下:
```python全局变量
d = 0
def sub(a, b):d 在这为局部变量
d = a - b
print(‘函数内 : ‘, d)
sub(9, 1)
print(‘函数外 : ‘, d)
#执行结果:
#函数内 : 8
#函数外 : 0
当内部作用域想要修改外部作用域的变量时,就要用到 `global` 和 `nonlocal` 关键字了,下面通过具体示例来了解一下。
如果我们想将上面示例中 `sub()` 函数中的 `d` 变量修改为全局变量,则需使用 `global` 关键字,示例如下所示:
```python
# 全局变量
d = 0
def sub(a, b):
# 使用 global 声明 d 为全局变量
global d
d = a - b
print('函数内 : ', d)
sub(9, 1)
print('函数外 : ', d)
#执行结果:
#函数内 : 8
#函数外 : 8
如果需要修改嵌套作用域中的变量,则需用到 nonlocal 关键字。
def outer():
d = 1
def inner():
d = 2
print('inner:', d)
inner()
print('outer:', d)
outer()
#执行结果:
#inner:2
#outer:1
使用 nonlocal
再来看一下使用了 nonlocal 关键字的执行情况,如下所示:
执行结果:
def outer():
d = 1
def inner():
nonlocal d
d = 2
print('inner:', d)
inner()
print('outer:', d)
outer()
#执行结果:
#inner:2
#outer:2
四、迭代器
1.迭代
我们知道 Python 中有一些对象可以通过 for 来循环遍历,比如:列表、元组、字符等,以字符串为例,如下所示:
for i in 'Hello':
print(i)
#执行结果:
H
e
l
l
o
这个遍历过程就是迭代。
2.可迭代对象
可迭代对象需具有 __iter__() 方法,它们均可使用 for 循环遍历,我们可以使用 isinstance() 方法来判断一个对象是否为可迭代对象,看下示例:
from collections import Iterable
print(isinstance('abc', Iterable))
print(isinstance({1, 2, 3}, Iterable))
print(isinstance(1024, Iterable))
#执行结果:
True
True
False
3.迭代器
迭代器需要具有 __iter__() 和 __next__() 两个方法,这两个方法共同组成了迭代器协议,通俗来讲迭代器就是一个可以记住遍历位置的对象,迭代器一定是可迭代的,反之不成立。
__iter__():返回迭代器对象本身__next__():返回下一项数据
迭代器对象本质是一个数据流,它通过不断调用 __next__() 方法或被内置的 next() 方法调用返回下一项数据,当没有下一项数据时抛出 StopIteration 异常迭代结束。上面我们说的 for 循环语句的实现便是利用了迭代器。
我们试着自己来实现一个迭代器,如下所示:
class MyIterator:
def __init__(self):
self.s = '程序之间'
self.i = 0
def __iter__(self):
return self
def __next__(self):
if self.i < 4:
n = self.s[self.i]
self.i += 1
return n
else:
raise StopIteration
mi = iter(MyIterator())
for i in mi:
print(i)
#输出结果:
程
序
之
间
伍、生成器
生成器是用来创建迭代器的工具,其写法与标准函数类似,不同之处在于返回时使用 yield 语句,关于 yield ,可以参考python中yield的用法详解——最简单,最清晰的解释,再来熟悉一下:
yield 是一个关键字,作用和 return 差不多,差别在于 yield 返回的是一个生成器(在 Python 中,一边循环一边计算的机制,称为生成器),它的作用是:有利于减小服务器资源,在列表中所有数据存入内存,而生成器相当于一种方法而不是具体的信息,用多少取多少,占用内存小。
生成器的创建方式有很多种,比如:使用 yield 语句、生成器表达式(可以简单的理解为是将列表的 [] 换成了 (),特点是更加简洁,但不够灵活)。看下示例:
1.示例 1
def foo():
print("starting...")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print("*"*20)
print(next(g))
#执行结果:
starting...
4
********************
res: None
4
a.程序开始执行以后,因为foo函数中有yield关键字,所以foo函数并不会真的执行,而是先得到一个生成器g(相当于一个对象)
b.直到调用next方法,foo函数正式开始执行,先执行foo函数中的print方法,然后进入while循环
c.程序遇到yield关键字,然后把yield想想成return,return了一个4之后,程序停止,并没有执行赋值给res操作,此时next(g)语句执行完成,所以输出的前两行(第一个是while上面的print的结果,第二个是return出的结果)是执行print(next(g))的结果
d.程序执行print("*"*20),输出20个*
e.又开始执行下面的print(next(g)),这个时候和上面那个差不多,不过不同的是,这个时候是从刚才那个next程序停止的地方开始执行的,也就是要执行res的赋值操作,这时候要注意,这个时候赋值操作的右边是没有值的(因为刚才那个是return出去了,并没有给赋值操作的左边传参数),所以这个时候res赋值是None,所以接着下面的输出就是res:None
f.程序会继续在while里执行,又一次碰到yield,这个时候同样return 出4,然后程序停止,print函数输出的4就是这次return出的4。
2.示例 2
def foo():
print("starting...")
while True:
res = yield 4
print("res:",res)
g = foo()
print(next(g))
print("*"*20)
print(g.send(7))
#执行结果:
starting...
4
********************
res: 7
4
大致说一下
send函数的概念:此时你应该注意到上面那个的紫色的字,还有上面那个res的值为什么是None,这个变成了7,到底为什么,这是因为,send是发送一个参数给res的,因为上面讲到,return的时候,并没有把4赋值给res,下次执行的时候只好继续执行赋值操作,只好赋值为None了,而如果用send的话,开始执行的时候,先接着上一次(return 4之后)执行,先把7赋值给了res,然后执行next的作用,遇见下一回的yield,return出结果后结束。
上面这个例子与前面例子差不多,区别在于执行g.send(7),程序会从yield关键字那一行继续向下运行,send会把7这个值赋值给res变量,由于send方法中包含next()方法,所以程序会继续向下运行执行print方法,然后再次进入while循环,程序执行再次遇到yield关键字,yield会返回后面的值后,程序再次暂停,直到再次调用next方法或send方法。
陆 装饰器
1.闭包
首先我们来了解下闭包,什么是闭包呢?看一下维基百科给出的解析:
闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例。
不过都没关系,我们再以 Python 为例更通俗的解释一下:比如我们调用一个带有返回值的函数 x,此时函数 x 为我们返回一个函数 y,这个函数 y 就被称作闭包,这么一说是不是豁然开朗了
def x(id):
def y(name):
print ('id:', id, 'name:', name)
return y
y = x('ityard')
y('程序之间')
通过上面的示例,我们会发现闭包与类有一些相似,比如:它们都能实现数据的封装、方法的复用等;此外,通过使用闭包可以避免使用全局变量,还能将函数与其所操作的数据关连起来。
2.装饰器
装饰器(decorator)也称装饰函数,是一种闭包的应用,其主要是用于某些函数需要拓展功能,但又不希望修改原函数,它就是语法糖,使用它可以简化代码、增强其可读性,当然装饰器不是必须要求被使用的,不使用也是可以的,Python 中装饰器通过 @ 符号来进行标识。
装饰器可以基于函数实现也可基于类实现,其使用方式基本是固定的,看一下基本步骤:
- 定义装饰函数(类)
- 定义业务函数
- 在业务函数上添加
@装饰函数(类)名
接下来通过示例来作进一步了解。
a.基于函数
# 装饰函数
def funA(flag):
def funB(fun):
def funC(*args, **kw):
if flag == True:
print('==========')
elif flag == False:
print('----------')
fun(*args, **kw)
return funC
return funB
@funA(False)
# 业务函数
def funD(name):
print('Hello', name)
funD('Jhon')
Python 中还支持多个装饰器同时使用,比如装饰函数为:funA、funD,业务函数为:funH,使用方式如下所示:
@funA
@funD
def funH():
...
b.基于类
装饰器除了基于函数实现,还可以基于类实现,看下示例:
class Test(object):
def __init__(self, func):
print('函数名是 %s ' % func.__name__)
self.__func = func
def __call__(self, *args, **kwargs):
self.__func()
@Test
def hello():
print('Hello ...')
hello()
Python 装饰器的 @... 相当于将被装饰的函数(业务函数)作为参数传入装饰函数(类)。
