
壹 概述
Go(又称Golang)是Google开发的一种静态强类型、编译型、并发型,并具有垃圾回收功能的多协程编程语言。罗伯特·格瑞史莫(Robert Griesemer),罗勃·派克(Rob Pike)及肯·汤普逊(Ken Thompson)于2007年9月开始设计Go,稍后Ian Lance Taylor、Russ Cox加入项目。Go是基于Inferno操作系统所开发的。Go于2009年11月正式宣布推出,成为开放源代码项目,并在Linux及Mac OS X平台上进行了实现,后来追加了Windows系统下的实现。在2016年,Go被软件评价公司TIOBE 选为“TIOBE 2016 年最佳语言”。 目前,Go每半年发布一个二级版本(即从a.x升级到a.y)。Go 语言语法与 C 相近,但功能上有:内存安全,GC(垃圾回收),结构形态及 CSP-style 并发计算。
Go语言的并发是基于 goroutine 的,goroutine 类似于线程,但并非线程,就是我们通常说的协程。可以将 goroutine 理解为一种虚拟线程。Go 语言运行时会参与调度 goroutine,并将 goroutine 合理地分配到每个 CPU 中,最大限度地使用CPU性能。开启一个goroutine的消耗非常小(大约2KB的内存),你可以轻松创建数百万个goroutine。
goroutine的特点:
a. goroutine具有可增长的分段堆栈。这意味着它们只在需要时才会使用更多内存。
b. goroutine的启动时间比线程快。
c. goroutine原生支持利用channel安全地进行通信。
d. goroutine共享数据结构时无需使用互斥锁。
说一个前提:该教程是go搭配了vscode学习的!
1.1 优缺点
a.优点
- 背靠大厂,google背书,可靠
- 天生支持并发(最显著特点)
- 语法简单,容易上手
- 内置runtime,支持垃圾回收
- 可直接编译成机器码,不依赖其他库
- 丰富的标准库
- 跨平台编译
go语言是号称像写Python代码(效率)一样编写C代码(性能)。
- b. 缺点
作为编译性语言调试不如脚本方便
在数据分析上没有脚本适用
对底层的控制没有基础语言灵活
1.2 用途
Go 语言被设计成一门应用于搭载 Web 服务器,存储集群或类似用途的巨型中央服务器的系统编程语言。对于高性能分布式系统领域而言,Go 语言无疑比大多数其它语言有着更高的开发效率。它提供了海量并行的支持,在服务端的开发优势较大,Go语言为并发而生。
贰 Go语言环境安装与开发工具
2.1 Go语言环境
Go 语言支持以下系统:
- Linux
- FreeBSD
- Mac OS X(也称为 Darwin)
- Windows
安装包下载地址为:https://golang.org/dl/或者https://go.dev/learn/
如果打不开可以使用这个地址:https://golang.google.cn/dl/。
各个系统对应的包名:
| 操作系统 | 包名 |
|---|---|
| Windows | go1.4.windows-amd64.msi |
| Linux | go1.4.linux-amd64.tar.gz |
| Mac | go1.4.darwin-amd64-osx10.8.pkg |
| FreeBSD | go1.4.freebsd-amd64.tar.gz |
2.2 开发工具
- vim
- sublime
- atom
- LiteIDE
- eclipse
- goland(最全的Go语言开发工具)
- vscode(本系列教程的主要开发工具)
详细安装:VSCode配置Go环境
叁 第一个Go程序
Go 语言的基础组成有6个部分组成:包声明、引入包、函数、变量、语句 & 表达式、注释
3.1 例子
实例:
package main
import "fmt"
func main() {
/*程序主体*/
fmt.Println("Hello, World!")
}
说明:
a.
package main:定义了该程序所在的包名。在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包,main包是程序入口包。
b.import "fmt":告诉 Go 编译器这个程序需要使用 fmt 包(函数或其他元素),fmt 包实现了格式化 IO(输入/输出)的函数。与package不同,这里是引用别的包,而package定义的是当前属于什么包
c.func main():程序开始执行的函数。main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数(如果有init()函数则会先执行该函数)。
d./*...*/:注释,在程序执行时将被忽略。单行注释是最常见的注释形式,你可以在任何地方使用以//开头的单行注释。多行注释也叫块注释,均已以/*开头,并以*/结尾,且不可以嵌套使用,多行注释一般用于包的文档描述或注释成块的代码片段。
e.fmt.Println(...):可以将字符串输出到控制台,并在最后自动增加换行字符 \n。
使用fmt.Print("hello, world\n")可以得到相同的结果。Println这两个函数也支持使用变量,如:fmt.Println(arr)。如果没有特别指定,它们会以默认的打印格式将变量 arr 输出到控制台。
f.当标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的public);标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的protected)。
3.2 执行 Go 程序
让我们来看下如何编写 Go 代码并执行它。步骤如下:
- a.打开编辑器如Sublime2,将以上代码添加到编辑器中。
- b.将以上代码保存为 hello.go
- c.打开命令行,并进入程序文件保存的目录中。
- d.输入命令 go run hello.go 并按回车执行代码。
- e.如果操作正确你将在屏幕上看到 “Hello World!” 字样的输出。
$ go run hello.go Hello, World! - f.我们还可以使用
go build命令来生成二进制文件:
**需要注意的是$ go build hello.go # 或者 go build -o hello hello.go $ ls hello hello.go $ ./hello Hello, World! # 对于编译出的程序是win或者linux,需要修改go配置里面的set GOOS=windows、set GOHOSTARCH=amd64选项{不能单独放在一行,所以以下代码在运行时会产生错误:package main import "fmt" func main() { // 错误,{ 不能在单独的行上 fmt.Println("Hello, World!") }
肆 Go语言基础语法
4.1 Go标记(语法说明)
Go程序可以由多个标记组成,可以是关键字,标识符,常量,字符串,符号。如以下 GO 语句由 6 个标记组成:
fmt.Println("Hello, World!")
/*
6个标记是:fmt、.、Println、(、"Hello, World!"、)
*/
4.2 行分隔符
在Go程序中,一行代表一个语句结束。每个语句不需要像 C 家族中的其它语言一样以分号;结尾,因为这些工作都将由 Go 编译器自动完成。
如果你打算将多个语句写在同一行,它们则必须使用;人为区分,但在实际开发中我们并不鼓励这种做法。
以下为两个语句:
fmt.Println("Hello, World!")
fmt.Println("菜鸟教程:runoob.com")
4.3 注释
注释不会被编译,每一个包应该有相关注释。单行注释是最常见的注释形式,你可以在任何地方使用以 // 开头的单行注释。多行注释也叫块注释,均已以 /* 开头,并以 */ 结尾。如:
// 单行注释
/*
Author by 菜鸟教程
我是多行注释
*/
4.4 标识符
标识符用来命名变量、类型等程序实体。一个标识符实际上就是一个或是多个字母(AZ和az)数字(0~9)、下划线_组成的序列,但是第一个字符必须是字母或下划线而不能是数字。
以下是有效的标识符:
mahesh kumar abc move_name a_123
myname50 _temp j a23b9 retVal
以下是无效的标识符:
- 1ab(以数字开头)
- case(Go 语言的关键字)
- a+b(运算符是不允许的)
4.5 关键字
下面列举了 Go 代码中会使用到的 25 个关键字或保留字:
| break | default | func | interface | select |
|---|---|---|---|---|
| case | defer | go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
除了以上介绍的这些关键字,Go 语言还有 37 个预定义标识符:
| 说明 | 保留字 |
|---|---|
| 常数 | true、false、iota、nil |
| 类型 | int、int8、int16、int32、int64、uint、uint8、uint16、uint32、uint64、uintptr、float32、float64、complex128、complex64、bool、byte、rune、string、error |
| 常用函数 | make、len、cap、new、append、copy、close、delete、complex、real、imag、panic、recover |
程序一般由关键字、常量、变量、运算符、类型和函数组成。程序中可能会使用到这些分隔符(都是英文格式):括号(),中括号[]和大括号{}。
程序中可能会使用到这些标点符号(都是英文格式):.、,、;、: 和 …。
4.6 Go 语言的空格
Go 语言中变量的声明必须使用空格隔开,如:var age int;
语句中适当使用空格能让程序更易阅读,以下是对比:
无空格:fruit=apples+oranges;
在变量与运算符间加入空格,程序看起来更加美观,如:fruit = apples + oranges;
4.7 Go的命名规范
参考这篇文章:Go语言编程之命名规范
4.7.1 包名称
保持package的名字和目录名一致,尽量采取有意义的包名,简短,有意义,尽量和标准库不要冲突。包名应该为小写单词,不要使用下划线或者混合大小写。
package file
package main
4.7.2 文件命名
尽量采取有意义的文件名,简短,有意义,应该为小写单词,使用下划线分隔各个单词。
approve_service.go
4.7.3 结构体命名
- 采用驼峰命名法,首字母根据访问控制大写或者小写
- struct 申明和初始化格式采用多行,例如下面:
type MainConfig struct {
Port string `json:"port"`
Address string `json:"address"`
}
config := MainConfig{"1234", "123.221.134"}
4.7.4 接口命名
- 命名规则基本和上面的结构体类型
- 单个函数的结构名以
er作为后缀,例如:Reader、Writer。
type Reader interface {
Read(p []byte) (n int, err error)
}
4.7.5 变量命名
和结构体类似,变量名称一般遵循驼峰法,首字母根据访问控制原则大写或者小写,但遇到特有名词时,需要遵循以下规则:
- 如果变量为私有,且特有名词为首个单词,则使用小写,如 appService
- 若变量类型为 bool 类型,则名称应以 Has、Is、Can或Allow开头
var isExist bool
var hasConflict bool
var canManage bool
var allowGitHook bool
4.6.6 常量命名
常量均需使用全部大写字母组成,并使用下划线分词
const APP_URL = "https://www.baidu.com"
如果是枚举类型的常量,需要先创建相应类型:
type Scheme string
const (
HTTP Scheme = "http"
HTTPS Scheme = "https"
)
伍 Go 语言变量
程序运行过程中的数据都是保存在内存中,我们想要在代码中操作某个数据时就需要去内存上找到这个变量,但是如果我们直接在代码中通过内存地址去操作变量的话,代码的可读性会非常差而且还容易出错,所以我们就利用变量将这个数据的内存地址保存起来,以后直接通过这个变量就能找到内存上对应的数据了。变量来源于数学,是计算机语言中能储存计算结果或能表示值抽象概念。变量可以通过变量名访问。Go 语言变量名由字母、数字、下划线组成,其中首个字符不能为数字。
声明变量的一般形式是使用 var 关键字:var 变量名 变量类型
可以一次声明多个变量:var 变量名1,变量名2 变量类型
5.1 变量声明
变量在指定变量类型时有三种变量声明:
- 如果没有初始化,则变量默认为零值
- 根据值自行判定变量类型。
- 省略 var, 注意 := 左侧如果没有声明新的变量,就产生编译错误,格式:
v_name := value
例如:
var intVal int
intVal :=1 // 这时候会产生编译错误,因为 intVal 已经声明,不需要重新声明
直接使用下面的语句即可:
intVal := 1 // 此时不会产生编译错误,因为有声明新的变量,因为 := 是一个声明语句
intVal := 1 相等于:
var intVal int
intVal = 1
可以将 var f string = “Runoob” 简写为 f := “Runoob”:
package main
import "fmt"
func main() {
f := "Runoob" // var f string = "Runoob"
fmt.Println(f)
}
//结果为:Runoob
但是我个人设置的话,可以直接var 变量名 = 值,而不用变量名 := 值
5.2 多变量声明
//类型相同多个变量, 非全局变量
var vname1, vname2, vname3 type
vname1, vname2, vname3 = v1, v2, v3
var vname1, vname2, vname3 = v1, v2, v3 // 和 python 很像,不需要显示声明类型,自动推断
vname1, vname2, vname3 := v1, v2, v3 // 出现在 := 左侧的变量不应该是已经被声明过的,否则会导致编译错误
// 这种因式分解关键字的写法一般用于声明全局变量
var (
变量名1 变量类型1
变量名2,变量名3 变量类型2
)
5.3 值类型和引用类型(有利于理解变量)
值类型:int、float、bool和string这些类型都属于值类型,使用这些类型的变量直接指向存在内存中的值,值类型的变量的值存储在栈中。
引用类型:特指slice、map、channel这三种预定义类型。引用类型拥有更复杂的存储结构:(1)分配内存 (2)初始化一系列属性等一个引用类型的变量r1存储的是r1的值所在的内存地址(数字),或内存地址中第一个字所在的位置,这个内存地址被称之为指针,这个指针实际上也被存在另外的某一个字中。
两者的主要区别:拷贝操作和函数传参。
在Go语言中对于引用类型的变量,我们在使用的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储。而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配内存,就引出来今天的new和make。 Go语言中new和make是内建的两个函数,主要用来分配内存。这些后面在指针中会详细讲解。
- 详细说明:
使用值类型的变量直接指向存在内存中的值:
当使用等号 = 将一个变量的值赋值给另一个变量时,如:j = i,实际上是在内存中将 i 的值进行了拷贝:
你可以通过 &i 来获取变量 i 的内存地址,例如:0xf840000040(每次的地址都可能不一样)。值类型的变量的值存储在栈中。
内存地址会根据机器的不同而有所不同,甚至相同的程序在不同的机器上执行后也会有不同的内存地址。因为每台机器可能有不同的存储器布局,并且位置分配也可能不同。
更复杂的数据通常会需要使用多个字,这些数据一般使用引用类型保存。
一个引用类型的变量 r1 存储的是 r1 的值所在的内存地址(数字),或内存地址中第一个字所在的位置。
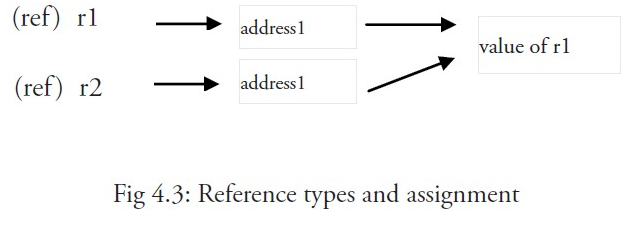
这个内存地址称之为指针,这个指针实际上也被存在另外的某一个值中。
同一个引用类型的指针指向的多个字可以是在连续的内存地址中(内存布局是连续的),这也是计算效率最高的一种存储形式;也可以将这些字分散存放在内存中,每个字都指示了下一个字所在的内存地址。
当使用赋值语句 r2 = r1 时,只有引用(地址)被复制。
如果 r1 的值被改变了,那么这个值的所有引用都会指向被修改后的内容,在这个例子中,r2 也会受到影响。
5.4 变量的初始化
Go语言在声明变量的时候,会自动对变量对应的内存区域进行初始化操作。每个变量会被初始化成其类型的默认值,例如: 整型和浮点型变量的默认值为0。 字符串变量的默认值为空字符串。 布尔型变量默认为false。chan、func、interface、map、slice 、指针变量的默认为nil。当然我们也可在声明变量的时候为其指定初始值。变量初始化的标准格式如下:
var 变量名 类型 = 表达式
// 由于go语言可以根据变量的值来推断其类型,所以我们可以省略类型说明符 [type]。
var 变量名 = 表达式
例子:
var name1 string = "A7"
var age1 int = 18
// 或者一次初始化多个变量
var name2, age2 = "A7cc", 20
5.5 简短形式,使用:=赋值操作符
我们知道可以在变量的初始化时省略变量的类型而由系统自动推断,声明语句写上 var 关键字其实是显得有些多余了,因此我们可以将它们简写为 a := 50 或 b := false。
a 和 b 的类型(int 和 bool)将由编译器自动推断。
这是使用变量的首选形式,但是它只能被用在函数体内,而不可以用于全局变量的声明与赋值。使用操作符 := 可以高效地创建一个新的变量,称之为初始化声明。
注意事项
如果在相同的代码块中,我们不可以再次对于相同名称的变量使用初始化声明,例如:a := 20 就是不被允许的,编译器会提示错误 no new variables on left side of :=,但是 a = 20 是可以的,因为这是给相同的变量赋予一个新的值。
如果你在定义变量 a 之前使用它,则会得到编译错误 undefined: a。
如果你声明了一个局部变量却没有在相同的代码块中使用它,同样会得到编译错误,例如下面这个例子当中的变量 a:
package main
import* "fmt"
func main() {
var a string = "abc"
fmt.Println("hello, world")
}
尝试编译这段代码将得到错误 a declared and not used。
此外,单纯地给 a 赋值也是不够的,这个值必须被使用,所以使用
fmt.Println("hello, world", a)
会移除错误。
但是全局变量是允许声明但不使用的。 同一类型的多个变量可以声明在同一行,如:
var a, b, c int
多变量可以在同一行进行赋值,如:
var a, b int
var c string
a, b, c = 5, 7, "abc"
上面这行假设了变量 a,b 和 c 都已经被声明,否则的话应该这样使用:
a, b, c := 5, 7, "abc"
右边的这些值以相同的顺序赋值右边的这些值以相同的顺序赋值给左边的变量,所以 a 的值是 5,b 的值是 7,c 的值是 “abc”。这被称为并行或同时赋值。如果你想要交换两个变量的值,则可以简单地使用 a, b = b, a,两个变量的类型必须是相同。:=不能使用在函数外。
什么时候使用长声明?什么时候使用长声明?
- 当需要全局变量或者不确定变量的值,但有需要变量时,可以进行变量长声明
- 当需要重复声明变量(这里需要注意必须有新变量产生)或者搭配for、if等语句时,可以进行变量短声明
5.6 匿名变量
在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线_表示,例如:
unc foo() (int, string) {
return 10, "Q1mi"
}
func main() {
x, _ := foo()
_, y := foo()
fmt.Println("x=", x)
fmt.Println("y=", y)
}
匿名变量实际上是一个只写变量,你不能得到它的值。这样做是因为 Go 语言中你必须使用所有被声明的变量,但有时你并不需要使用从一个函数得到的所有返回值,匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。例子就是并行赋值,并行赋值也被用于当一个函数返回多个返回值时,比如这里的 val 和错误 err 是通过调用 Func1 函数同时得到:val, err = Func1(var1)。
陆 Go 语言常量
常量是一个简单值的标识符,在程序运行时,不会被修改的量。常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
常量的定义格式:const identifier [type] = value
6.1 常量定义
你可以省略类型说明符 [type],因为编译器可以根据变量的值来推断其类型。
- 显式类型定义: const b string = “abc”
- 隐式类型定义: const b = “abc”
多个相同类型的声明可以简写为:const c_name1, c_name2 = value1, value2
以下实例演示了常量的应用:
package main
import "fmt"
func main() {
const LENGTH int = 10
const WIDTH int = 5
var area int
const a, b, c = 1, false, "str" //多重赋值
area = LENGTH * WIDTH
fmt.Printf("面积为 : %d", area)
println()
println(a, b, c)
}
/*结果为:面积为 : 50
1 false str*/
const同时声明多个常量时,如果省略了值则表示和上面一行的值相同。 例如:
const (
n1 = 100
n2
n3
)
上面示例中,常量n1、n2、n3的值都是100。
6.2 枚举
常量还可以用作枚举:
const (
Unknown = 0
Female = 1
Male = 2
)
数字 0、1 和 2 分别代表未知性别、女性和男性。
常量可以用len(), cap(), unsafe.Sizeof()函数计算表达式的值。常量表达式中,函数必须是内置函数,否则编译不过:
package main
import "unsafe"
const (
a = "abc"
b = len(a)
c = unsafe.Sizeof(a)
)
func main(){
println(a, b, c)
}
//结果为:abc 3 16
6.3 iota
iota是go语言的常量计数器,只能在常量的表达式中使用。iota在const关键字出现时将被重置为0。const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
iota 可以被用作枚举值:
const (
a = iota
b = iota
c = iota
)
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
const (
a = iota
b
c
)
iota 用法
package main
import "fmt"
func main() {
const (
a = iota //0
b //1
c //2
d = "ha" //独立值,iota += 1
e //"ha" iota += 1
f = 100 //iota +=1
g //100 iota +=1
h = iota //7,恢复计数
i //8
_ //使用_跳过该值,iota +=1
k //9,恢复计数
)
fmt.Println(a, b, c, d, e, f, g, h, i, k)
}
//结果为:0 1 2 ha ha 100 100 7 8 10
再看个有趣的的 iota 实例:
package main
import "fmt"
const (
i=1<<iota
j=3<<iota
k
l
)
func main() {
fmt.Println("i=",i)
fmt.Println("j=",j)
fmt.Println("k=",k)
fmt.Println("l=",l)
}
/*
i= 1
j= 6
k= 12
l= 24
*/
iota 表示从 0 开始自动加 1,所以 i=1<<0, j=3<<1(<<表示左移的意思),即:i=1, j=6,这没问题,关键在 k 和 l,从输出结果看 k=3<<2,l=3<<3。
简单表述:
i=1:左移 0 位,不变仍为 1;
- j=3:左移 1 位,变为二进制 110, 即 6;
- k=3:左移 2 位,变为二进制 1100, 即 12;
- l=3:左移 3 位,变为二进制 11000,即 24。
注:**<<n==*(2^n)**。
多个iota定义在一行,都会初始化为0,然后慢慢增加:
const (
a, b = iota + 1, iota + 3 //1,2
c, d //2,4
e, f //3,5
)
柒 Go语言数据类型
在 Go 编程语言中,数据类型用于声明函数和变量。数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。
Go语言按类别有以下几种数据类型:
| 序号 | 类型和描述 |
|---|---|
| 1 | 布尔型:布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true。 |
| 2 | 数字类型:整型 int 和浮点型 float32、float64,Go 语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。 |
| 3 | 字符串类型:字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。 |
| 4 | 派生类型:指针类型(Pointer)、数组类型、结构化类型(struct)、Channel类型、函数类型、切片类型、接口类型(interface)、Map类型 |
7.1 数字类型
7.1.1 整型与特殊整型
整型分为以下两个大类: 按长度分为:int8、int16、int32、int64 对应的无符号整型:uint8、uint16、uint32、uint64
其中,uint8就是我们熟知的byte型,int16对应C语言中的short型,int64对应C语言中的long型。
| 类型 | 类型和描述 |
|---|---|
| uint8 | 无符号8位整型(0到255) |
| uint16 | 无符号16位整型(0到65535) |
| uint32 | 无符号32位整型(0到4294967295) |
| uint64 | 无符号64位整型(0到18446744073709551615) |
| int8 | 有符号8位整型(-128到127) |
| int16 | 有符号16位整型(-32768到32767) |
| int32 | 有符号32位整型(-2147483648 到 2147483647) |
| int64 | 有符号64位整型(-9223372036854775808到9223372036854775807) |
- 特殊整型
| 类型 | 描述 |
|---|---|
| uint | 32位操作系统上就是uint32,64位操作系统上就是uint64 |
| int | 32位操作系统上就是int32,64位操作系统上就是int64 |
| uintptr | 无符号整型,用于存放一个指针 |
注意: 在使用int和 uint类型时,不能假定它是32位或64位的整型,而是考虑int和uint可能在不同平台上的差异。实际使用中,切片或 map 的元素数量等都可以用int来表示。在涉及到二进制传输、读写文件的结构描述时,为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用int和 uint。
- 数字字面量语法
Go1.13版本之后引入了数字字面量语法,这样便于开发者以二进制、八进制或十六进制浮点数的格式定义数字,例如:v := 0b00101101, 代表二进制的 101101,相当于十进制的 45。 v := 0o377,代表八进制的 377,相当于十进制的 255。 v := 0x1p-2,代表十六进制的 1 除以 2²,也就是 0.25。
而且还允许我们用 _ 来分隔数字,比如说: v := 123_456 表示 v 的值等于 123456。
7.1.2 浮点型和复数
| 序号 | 类型和描述 |
|---|---|
| float32 | 遵循IEEE-754标准,32位浮点型数,最大范围3.4e38,常量为:math.MaxFloat3 |
| float64 | 遵循IEEE-754标准,64位浮点型数,最大范围1.8e308,常量为:math.MaxFloat64 |
| complex64 | 32位实数和虚数 |
| complex128 | 64位实数和虚数 |
7.1.3 布尔值
Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值。
注意:
a. 布尔类型变量的默认值为false。
b. Go 语言中不允许将整型强制转换为布尔型.
c. 布尔型无法参与数值运算,也无法与其他类型进行转换。
7.1.4 字符串
Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。 Go 语言里的字符串的内部实现使用UTF-8编码。 字符串的值为双引号(")中的内容,可以在Go语言的源码中直接添加非ASCII码字符,例如:
s1 := "hello"
s2 := "你好"
- 字符串转义符
Go 语言的字符串常见转义符包含回车、换行、单双引号、制表符等,如下表所示。
| 转义符 | 含义 |
|---|---|
\r |
回车符(重新回到行首) |
\n |
换行符(直接跳到下一行的同列位置) |
\t |
制表符 |
\' |
单引号 |
\" |
双引号 |
\\ |
反斜杠 |
举个例子,我们要打印一个Windows平台下的一个文件路径:
package main
import (
"fmt"
)
func main() {
fmt.Println("str := \"c:\\Code\\lesson1\\go.exe\"")
}
- 多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符:
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
反引号间换行自动在输出时换行,而所有的转义字符均无效,文本将会原样输出。
- 字符串的常用操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
+或fmt.Sprintf |
拼接字符串 |
| strings.Split(s, sep) | 分割 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
a := "a123123123"
b := "b456456"
var c = []string{"12", "34"}
fmt.Printf("a的长度%d", len(a))
fmt.Println("1234" + "56789")
// strings.Split(s, sep)函数用于将指定的分隔符切割字符串,并返回切割后的字符串切片。
// s表示待分割的字符串
// sep表示分隔符
// 返回一个字符串切片。
fmt.Println(strings.Split(b, "4")) // [b 56 56]
// strings.Contains(str,s)判断str中是否包含个子串s。包含或者str为空则返回true
fmt.Println(strings.Contains(a, "12")) //true
// strings.HasPrefix(s, prefix)函数用来检测字符串是否以指定的前缀开头,strings.HasSuffix(s, suffix)是后缀
// s表示待检测的字符串
// prefix表示指定的前缀
// suffix表示指定的后缀
// 返回一个布尔值。如果字符串s是以prefix开头/以suffix结尾,则返回true,否则返回false。
fmt.Println(strings.HasPrefix(b, "b")) //true
fmt.Println(strings.HasSuffix(b, "6")) //true
// strings.Index(str,s)函数是返回子串出现的位置
// 返回子串str在字符串s中第一次出现的位置。
// 如果找不到则返回-1;如果str为空,则返回0
fmt.Println(strings.Index(b, "5")) //2
// strings.Join(str,s)函数是将str字符串切片中的子串连接成一个单独的字符串,子串之间用s分隔。
fmt.Println(strings.Join(c, "|")) //12|34
7.1.5 byte和rune类型
组成每个字符串的元素叫做字符(byte),可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(')包裹起来,如:
var a = '中'
var b = 'x'
Go 语言的字符有以下两种:
uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。rune类型,代表一个UTF-8字符。
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。
Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理。因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。
字符串底层是一个byte数组,所以可以和[]byte类型相互转换。字符串是不能修改的,,字符串是由byte字节组成,所以字符串的长度是byte字节的长度。 rune类型用来表示utf8字符,一个rune字符由一个或多个byte组成。
7.1.6 修改字符串
要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
func main() {
s1 := "big"
// 强制类型转换,将字符串强制转换为字符数组
byteS1 := []byte(s1)
// 修改了第一个字节为p
byteS1[0] = 'p'
fmt.Println(string(byteS1))
s2 := "白萝卜"
runeS2 := []rune(s2)
// 修改了第一个rune类型为红
runeS2[0] = '红'
fmt.Println(string(runeS2))
}
7.2 强制转换类型
有的时候我们需要将整型转换成浮点数,那么我们只需要将一种数据类型的变量转换为另外一种类型的变量。Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
type_name(expression)
//type_name 为类型,expression 为表达式,类型就是上面说的那些
人狠话不多,上例子:
package main
import "fmt"
func main() {
//定义一个a整型数和一个b浮点数
a, b := 1, 1.9
//输出函数
//这里的强制转换类型函数就是前面对应的类型名,用就行
fmt.Println("a浮点数值:", float64(a))
//可以发现当浮点数转成整型时,直接将小数点后面的值去掉了
fmt.Println("b整型数值:", int(b))
// a = 1
// b = 1
}
捌 变量的输出输入与格式化
对应输入输出,我们需要用到fmt标准库(理解为存放很多函数的仓库),fmt包实现了类似C语言printf和scanf的格式化I/O。主要分为向外输出内容和获取输入内容两大部分。
8.1 输出
8.1.1 Print系列输出——终端输出
Print系列函数会将内容输出到系统的标准输出。区别在于Print函数直接输出内容,Printf函数支持格式化输出字符串,Println函数会在输出内容的结尾添加一个换行符。
func Print(a ...interface{}) (n int, err error)
func Printf(format string, a ...interface{}) (n int, err error)
func Println(a ...interface{}) (n int, err error)
举个简单的例子:
package main
import (
// 在使用fmt库内的函数一定要引用fmt库
"fmt"
)
func main() {
fmt.Print("在终端打印该信息。")
name := "A7cc"
fmt.Printf("我是:%s\n", name)
fmt.Println("在终端打印单独一行显示,然后换行!")
fmt.Printf("换行了!")
}
8.1.2 Fprint系列输出——文件输出
Fprint系列函数会将内容输出到一个io.Writer接口类型的变量w中,我们通常用这个函数往文件中写入内容,同样有三种格式,功能和Print系列输出类型一样。
func Fprint(w io.Writer, a ...interface{}) (n int, err error)
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
func Fprintln(w io.Writer, a ...interface{}) (n int, err error)
举个例子:
fmt.Fprint(os.Stdout, "向标准输出写入内容1") // 直接在终端输出:向标准输出写入内容1
// 向标准输出写入内容
fmt.Fprintln(os.Stdout, "向标准输出写入内容2")// 直接在终端输出:向标准输出写入内容2
// 打开一个xx.txt文件
fileObj, err := os.OpenFile("./xx.txt", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
fmt.Println("打开文件出错,err:", err)
return
}
name := "A7cc"
// 向打开的文件句柄中写入内容
fmt.Fprintf(fileObj, "往文件中写如信息:%s", name)// 在当前目录下生成一个文件xx.txt,内容为:往文件中写如信息:A7cc
注意:只要满足io.Writer接口的类型都支持写入。
8.1.3 Sprint系列输出——返回字符串类型
Sprint系列函数会把传入的数据生成并返回一个字符串,同样有三种格式,功能和Print系列输出类型一样。
func Sprint(a ...interface{}) string
func Sprintf(format string, a ...interface{}) string
func Sprintln(a ...interface{}) string
简单的示例代码如下:
s1 := fmt.Sprint("A7cc")
name := "A7ccc"
age := 18
s2 := fmt.Sprintf("name:%s,age:%d", name, age)
s3 := fmt.Sprintln("A7cccc")
fmt.Printf("s1类型=%T,s2类型=%T,s3类型=%T", s1, s2, s3) // s1类型=string,s2类型=string,s3类型=string
8.1.4 Errorf系列输出——自定义错误输出
Errorf函数根据format参数生成格式化字符串并返回一个包含该字符串的错误。
func Errorf(format string, a ...interface{}) error
通常使用这种方式来自定义错误类型,例如:
err := errors.New("原始错误e")
err := fmt.Errorf("这是一个错误%v",err)
但是上面的方式会丢失原有的错误类型,只拿到错误描述的文本信息。为了不丢失函数调用的错误链,Go1.13版本为fmt.Errorf函数新加了一个%w占位符用来生成一个可以包裹Error的Wrapping Error,可以实现基于已有的错误再包装得到一个新的错误。
err := errors.New("原始错误e")
w := fmt.Errorf("Wrap了一个错误%w", err)
8.2 格式化占位符
*printf系列函数都支持format格式化参数,在这里我们按照占位符将被替换的变量类型划分,方便查询和记忆。
- 通用占位符
| 占位符 | 说明 |
|---|---|
| %v | 值的默认格式表示 |
| %+v | 类似%v,但输出结构体时会添加字段名 |
| %#v | 值的Go语法表示 |
| %T | 打印值的类型 |
| %% | 百分号 |
- 布尔型
| 占位符 | 说明 |
|---|---|
| %t | true或false |
- 整型
| 占位符 | 说明 |
|---|---|
| %b | 表示为二进制 |
| %c | 该值对应的unicode码值 |
| %d | 表示为十进制 |
| %o | 表示为八进制 |
| %x | 表示为十六进制,使用a-f |
| %X | 表示为十六进制,使用A-F |
| %U | 表示为Unicode格式:U+1234,等价于”U+%04X” |
| %q | 该值对应的单引号括起来的go语法字符字面值,必要时会采用安全的转义表示 |
- 浮点数与复数
| 占位符 | 说明 |
|---|---|
| %b | 无小数部分、二进制指数的科学计数法,如-123456p-78 |
| %e | 科学计数法,如-1234.456e+78 |
| %E | 科学计数法,如-1234.456E+78 |
| %f | 有小数部分但无指数部分,如123.456 |
| %F | 等价于%f |
| %g | 根据实际情况采用%e或%f格式(以获得更简洁、准确的输出) |
| %G | 根据实际情况采用%E或%F格式(以获得更简洁、准确的输出) |
- 字符串和
[]byte
| 占位符 | 说明 |
|---|---|
| %s | 直接输出字符串或者[]byte |
| %q | 该值对应的双引号括起来的go语法字符串字面值,必要时会采用安全的转义表示 |
| %x | 每个字节用两字符十六进制数表示(使用a-f |
| %X | 每个字节用两字符十六进制数表示(使用A-F) |
- 指针
| 占位符 | 说明 |
|---|---|
| %p | 表示为十六进制,并加上前导的0x |
- 宽度标识符
宽度通过一个紧跟在百分号后面的十进制数指定,如果未指定宽度,则表示值时除必需之外不作填充。精度通过(可选的)宽度后跟点号后跟的十进制数指定。如果未指定精度,会使用默认精度;如果点号后没有跟数字,表示精度为0。举例如下:
| 占位符 | 说明 |
|---|---|
| %f | 默认宽度,默认精度 |
| %9f | 宽度9,默认精度 |
| %.2f | 默认宽度,精度2 |
| %9.2f | 宽度9,精度2 |
| %9.f | 宽度9,精度0 |
- 其他flag
| 占位符 | 说明 |
|---|---|
+ |
总是输出数值的正负号;对%q(%+q)会生成全部是ASCII字符的输出(通过转义); |
/- |
对数值,正数前加空格而负数前加负号;对字符串采用%x或%X时(% x或% X)会给各打印的字节之间加空格 |
- |
在输出右边填充空白而不是默认的左边(即从默认的右对齐切换为左对齐); |
# |
八进制数前加0(%#o),十六进制数前加0x(%#x)或0X(%#X),指针去掉前面的0x(%#p)对%q(%#q),对%U(%#U)会输出空格和单引号括起来的go字面值; |
0 |
使用0而不是空格填充,对于数值类型会把填充的0放在正负号后面; |
例子:
```go
package main
import (
“fmt”
)
func main() {
// 定义一个类型,这里这个后面章节会讲,可以理解为一个自定义类型
o := struct{ name string }{“A7cc”}
fmt.Printf(“%v\n”, o)
fmt.Printf(“%#v\n”, o)
f := 65
fmt.Printf(“%b\n”, f)
n := 12.34
fmt.Printf(“%b\n”, n)
s := “A7cc”
fmt.Printf(“%s\n”, s)
fmt.Printf(“%p\n”, &o)fmt.Printf(“%f\n”, n)
fmt.Printf(“%9f\n”, n)
fmt.Printf(“%.2f\n”, n)
fmt.Printf(“%9.2f\n”, n)
fmt.Printf(“%9.f\n”, n)fmt.Printf(“%s\n”, s)
fmt.Printf(“%5s\n”, s)
fmt.Printf(“%-5s\n”, s)
fmt.Printf(“%5.7s\n”, s)
fmt.Printf(“%-5.7s\n”, s)
fmt.Printf(“%5.2s\n”, s)
fmt.Printf(“%05s\n”, s)
}
## 8.3 输入
Go语言`fmt`包下有`fmt.Scan`、`fmt.Scanf`、`fmt.Scanln`三个函数,可以在程序运行过程中从标准输入获取用户的输入。
### 8.3.1 fmt.Scan——普通的输入
`fmt.Scan`从标准输入中扫描用户输入的数据,将以空白符分隔的数据分别存入指定的参数。
函数格式如下:
```go
func Scan(a ...interface{}) (n int, err error)
- Scan从标准输入扫描文本,读取由空白符分隔的值保存到传递给本函数的参数中,换行符视为空白符。
- 本函数返回成功扫描的数据个数和遇到的任何错误。如果读取的数据个数比提供的参数少,会返回一个错误报告原因。
具体代码示例如下:
func main() {
var (
name string
age int
married bool
)
num, _ := fmt.Scan(&name, &age, &married)
fmt.Printf("扫描结果 name:%s age:%d married:%t \n有%d个参数", name, age, married, num)
}
将上面的代码编译后在终端执行,在终端依次输入A7cc、18和false使用空格分隔。
$ ./scan_demo
A7cc 18 false
扫描结果 name:A7cc age:18 married:false
有3个参数
8.3.2 fmt.Scanf——指定内容输入
fmt.Scanf为输入数据指定了具体的输入内容格式,只有按照格式输入数据才会被扫描并存入对应变量。
函数格式如下:
func Scanf(format string, a ...interface{}) (n int, err error)
- Scanf从标准输入扫描文本,根据format参数指定的格式去读取由空白符分隔的值保存到传递给本函数的参数中。
- 本函数返回成功扫描的数据个数和遇到的任何错误。
代码示例如下:
func main() {
var (
name string
age int
married bool
)
fmt.Scanf("1:%s 2:%d 3:%t", &name, &age, &married)
fmt.Printf("扫描结果 name:%s age:%d married:%t \n", name, age, married)
}
将上面的代码编译后在终端执行,在终端按照指定的格式依次输入小王子、28和false。
$ ./scan_demo
1:A7cc 2:18 3:false
扫描结果 name:A7cc age:18 married:false
fmt.Scanf不同于fmt.Scan简单的以空格作为输入数据的分隔符。
例如,我们还是按照上个示例中以空格分隔的方式输入,fmt.Scanf就不能正确扫描到输入的数据。
$ ./scan_demo
A7cc 18 false
扫描结果 name: age:0 married:false
8.3.3 fmt.Scanln
fmt.Scanln遇到回车就结束扫描了,比较常用。
函数签名如下:
func Scanln(a ...interface{}) (n int, err error)
- Scanln类似Scan,它在遇到换行时才停止扫描。最后一个数据后面必须有换行或者到达结束位置。
- 本函数返回成功扫描的数据个数和遇到的任何错误。
具体代码示例如下:
func main() {
var (
name string
age int
married bool
)
fmt.Scanln(&name, &age, &married)
fmt.Printf("扫描结果 name:%s age:%d married:%t \n", name, age, married)
}
将上面的代码编译后在终端执行,在终端依次输入小王子、28和false使用空格分隔。
$ ./scan_demo
A7cc 18
// 不输入第三个参数,直接回车,由于married默认值是空,所以为false
扫描结果 name:A7cc age:18 married:false
8.3.4 bufio.NewReader
有时候我们想完整获取输入的内容,而输入的内容可能包含空格,这种情况下可以使用bufio包来实现。示例代码如下:
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
func main() {
reader := bufio.NewReader(os.Stdin) // 从标准输入生成读对象
fmt.Print("请输入内容:")
text, _ := reader.ReadString('\n') // 读到换行
text = strings.TrimSpace(text)
fmt.Printf("%#v\n", text)
}
8.3.5 Fscan系列
这几个函数功能分别类似于fmt.Scan、fmt.Scanf、fmt.Scanln三个函数,只不过它们不是从标准输入中读取数据而是从io.Reader中读取数据,比如我们打开一个文件,就需要该系列。
func Fscan(r io.Reader, a ...interface{}) (n int, err error)
func Fscanln(r io.Reader, a ...interface{}) (n int, err error)
func Fscanf(r io.Reader, format string, a ...interface{}) (n int, err error)
8.3.6 Sscan系列
这几个函数功能分别类似于fmt.Scan、fmt.Scanf、fmt.Scanln三个函数,只不过它们不是从标准输入中读取数据而是从指定字符串中读取数据。
func Sscan(str string, a ...interface{}) (n int, err error)
func Sscanln(str string, a ...interface{}) (n int, err error)
func Sscanf(str string, format string, a ...interface{}) (n int, err error)
玖 变量作用域
作用域为已声明标识符所表示的常量、类型、变量、函数或包在源代码中的作用范围。
Go 语言中变量可以在三个地方声明:
- 函数内定义的变量称为局部变量
- 函数外定义的变量称为全局变量
- 函数定义中的变量称为形式参数
接下来让我们具体了解局部变量、全局变量和形式参数。
9.1 局部变量
在函数体内声明的变量称之为局部变量,它们的作用域只在函数体内,参数和返回值变量也是局部变量。
以下实例中 main() 函数使用了局部变量 a,b,c:
实例
package main
import "fmt"
func main() {
/* 声明局部变量 */
var a, b, c int
/* 初始化参数 */
a = 10
b = 20
c = a + b
fmt.Printf ("结果:a = %d, b = %d and c = %d\n", a, b, c)
}
9.2 全局变量
在函数体外声明的变量称之为全局变量,全局变量可以在整个包甚至外部包(被导出后)使用。
全局变量可以在任何函数中使用,以下实例演示了如何使用全局变量:
package main
import "fmt"
func main() {
/* 声明局部变量 */
var a, b, c int
/* 初始化参数 */
a = 10
b = 20
c = a + b
fmt.Printf("结果:a = %d, b = %d and c = %d\n", a, b, c)
}
Go 语言程序中全局变量与局部变量名称可以相同,但是函数内的局部变量会被优先考虑。
9.3 形式参数
形式参数会作为函数的局部变量来使用。实例如下:
package main
import "fmt"
/* 声明全局变量 */
var a int = 20;
func main() {
/* main 函数中声明局部变量 */
var a int = 10
var b int = 20
var c int = 0
fmt.Printf("main()函数中 a = %d\n", a);
c = sum( a, b);
fmt.Printf("main()函数中 c = %d\n", c);
}
/* 函数定义-两数相加 */
func sum(a, b int) int {
fmt.Printf("sum() 函数中 a = %d\n", a);
fmt.Printf("sum() 函数中 b = %d\n", b);
return a + b;
}
9.4 初始化局部和全局变量
不同类型的局部和全局变量默认值为:
| 数据类型 | 初始化默认值 |
|---|---|
| int | 0 |
| float32 | 0 |
| pointer | nil |
拾 Go语言运算符
运算符用于在程序运行时执行数学或逻辑运算。
Go 语言内置的运算符有:
- a. 算术运算符
- b. 关系运算符
- c. 逻辑运算符
- d. 位运算符
- e. 赋值运算符
- f. 其他运算符
10.1 算术运算符
下表列出了所有Go语言的算术运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A + B 输出结果 30 |
| - | 相减 | A - B 输出结果 -10 |
| * | 相乘 | A * B 输出结果 200 |
| / | 相除 | B / A 输出结果 2 |
| % | 求余 | B % A 输出结果 0 |
注意: ++(自增)和--(自减)在Go语言中是单独的语句,并不是运算符。
10.2 关系运算符
下表列出了所有Go语言的关系运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 | (A == B) 为 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False。 | (A != B) 为 True |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 | (A > B) 为 False |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False。 | (A < B) 为 True |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 | (A >= B) 为 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 | (A <= B) 为 True |
10.3 逻辑运算符
下表列出了所有Go语言的逻辑运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 | (A && B) 为 False |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 | (A || B) 为 True |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 | !(A && B) 为 True |
10.4 位运算符
位运算符对整数在内存中的二进制位进行操作。下表列出了位运算符 &、 | 和 ^的计算:
| p | q | p & q | p | q | p ^ q | ^p | p &^ q |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | -1 | 0 |
| 0 | 1 | 0 | 1 | 1 | -1 | 0 |
| 1 | 1 | 1 | 1 | 0 | -2 | 0 |
| 1 | 0 | 0 | 1 | 1 | -2 | 1 |
Go 语言支持的位运算符如下表所示(A为61,B为249):
| 运算符 | 描述 | 实例 |
|---|---|---|
& |
按位与运算符&是双目运算符。其功能是参与运算的两数各对应的二进位相与,口诀:全1为1,否则为0。 |
(A & B) 结果为57, 二进制为0011 1001 |
| ` | ` | 按位或运算符` |
^ |
当^是双目运算符按位异或运算符表示。其功能是参与运算的两数各对应的二进位相异或,口诀:相同为0,不同为1。 |
(A ^ B) 结果为196, 二进制为1100 0100 |
^ |
当^是单目运算符按取反运算符表示。其功能是参与单个数进行取反运算。 |
(^A) 结果为-62 |
&^ |
&^是双目运算符中的位清移运算符。其功能是将运算符左边数据相异的位保留,相同位清零,该运算符等同于A & (^B)。 |
(A &^ B) 结果为4, 二进制为0000 0100 |
<< |
左移运算符<<是双目运算符。左移n位就是乘以2的n次方。其功能把<<左边的运算数的各二进位全部左移若干位,由<<右边的数指定移动的位数。 |
B << 2 结果为996 ,二进制为0011 1110 0100 |
>> |
右移运算符>>是双目运算符。右移n位就是除以2的n次方。其功能是把>>左边的运算数的各二进位全部右移若干位,>>右边的数指定移动的位数。 |
B >> 2 结果为62 ,二进制为11 1110 |
PS:注意^使用的场景,是单目运算还是双目运算!
10.5 赋值运算符
下表列出了所有Go语言的赋值运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
= |
简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
+= |
相加后再赋值 | C += A 等于 C = C + A |
-= |
相减后再赋值 | C -= A 等于 C = C - A |
*= |
相乘后再赋值 | C *= A 等于 C = C * A |
/= |
相除后再赋值 | C /= A 等于 C = C / A |
%= |
求余后再赋值 | C %= A 等于 C = C % A |
<<= |
左移后赋值 | C <<= 2 等于 C = C << 2 |
>>= |
右移后赋值 | C >>= 2 等于 C = C >> 2 |
&= |
按位与后赋值 | C &= 2 等于 C = C & 2 |
^= |
按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
|= |
按位或后赋值 | C |= 2 等于 C = C | 2 |
10.6 其他运算符
下表列出了Go语言的其他运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
& |
返回变量存储地址,可以发下与位运算符的&一样,但是位运算符需要空格隔开 | &a;将给出变量的实际地址。 |
* |
指针变量。 | *a;是一个指针变量 |
10.7 运算符优先级
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
| 优先级 | 运算符 |
|---|---|
| 5 | *、/、%、<<、>>、&、&^ |
| 4 | `+ - |
| 3 | ==、!=、<、<=、>、>= |
| 2 | && |
| 1 | ` |
10.8 其他符号
单引号:单引号在go语言中表示golang中的
rune(int32)类型,单引号里面是单个字符,对应的值为改字符的ASCII值。func main() { a := 'A' fmt.Println(a) } // 65双引号:在go语言中双引号里面可以是单个字符也可以是字符串,双引号里面可以有转义字符,如
\n、\r等,对应go语言中的string类型。func main() { a := "Hello golang\nI am random_wz." fmt.Println(a) } // Hello golang // I am random_wz.反引号:反引号中的字符表示其原生的意思,在单引号中的内容可以是多行内容,不支持转义。
func main() {
a := `Hello golang\n:
I am random_wz.
Good.`
fmt.Println(a)
}
// Hello golang\n:
// I am random_wz.
// Good.
拾壹 常用函数
| 函数 | 说明 |
|---|---|
| unsafe.Sizeof(变量) | 查看变量所占空间,单位字节 |
| close | 主要用来关闭channel |
| len | 用来求长度,比如string、array、slice、map、channel,在复杂类型章节有具体说明 |
| new | 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针,在指针章节有具体说明 |
| make | 用来分配内存,主要用来分配引用类型,比如chan、map、slice,在复杂类型章节有具体说明 |
| append | 用来追加元素到数组、slice中,在复杂类型章节有具体说明 |
| panic和recover | 用来做错误处理 |
拾贰 其他
未完待续。。。。
